
Właśnie dlatego opracowali model, który rozumie podstawowe relacje pomiędzy obiektami. Główną rolę odgrywa w tym przypadku model, który reprezentuje poszczególne relacje pojedynczo, by później połączyć je w całość. W efekcie powstają dokładniejsze obrazy oparte na opisach tekstowych, nawet jeśli obiektów jest wiele i występują między nimi różne zależności.
Czytaj też: Oduczanie maszynowe – czy maszyny są w stanie zapominać?
Za tym potencjalnym przełomem stoi Yilun Du oraz jego współpracownicy: Shuang Li, Nan Liu, Joshua B. Tenenbaum oraz Antonio Torralba. Opracowane przez nich rozwiązanie jest w stanie wygenerować obraz otoczenia na podstawie tekstowego opisu obiektów i ich relacji. Za przykład mogą posłużyć dwa zdania, takie jak na przykład: Drewniany stół na lewo od niebieskiego stołka. Czerwona kanapa na prawo od niebieskiego stołka.

Dzięki wysiłkom członków zespołu badawczego, roboty mogłyby skuteczniej wykonywać skomplikowane, wieloetapowe zadania związane na przykład z układaniem przedmiotów w magazynie czy montażem urządzeń. Poza tym, maszyny mogłyby jeszcze lepiej się uczyć i pojmować interakcje z otoczeniem w sposób bardziej zbliżony do ludzkiego. Jak wyjaśnia Li, dzięki rozbiciu zdań na krótsze części dla każdej relacji, system może łączyć je na różne sposoby. W efekcie może lepiej dostosować się do opisów scen, których wcześniej nie widział.
Czytaj też: Model wykorzystujący uczenie maszynowe miał dawać etyczne porady. Okazał się rasistą
Inne systemy rozpatrują wszystkie relacje całościowo i generują obraz na podstawie opisu. Takie podejście jednak zawodzi, kiedy opisy są nietypowe, na przykład z większą liczbą relacji, ponieważ model ten nie jest w stanie przystosować się do generowania obrazów zawierających więcej relacji. Jako że składamy te oddzielne, mniejsze modele razem, możemy modelować większą liczbę relacji i dostosowywać się do nowych kombinacji. Yilun Du
Dzięki nowemu modelowi roboty będą mogły zrozumieć interakcje w podobny sposób jak ludzie
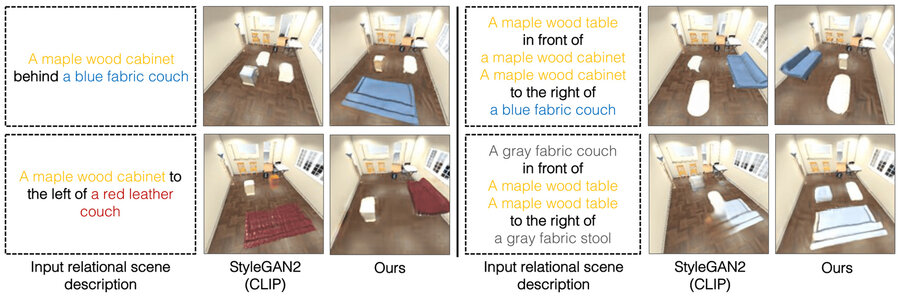
Ale na tym nie koniec. Model jest również w stanie działać w drugą stronę: mając obraz, może znaleźć opisy tekstowe, które pasują do relacji pomiędzy obiektami. Poza tym, system może być użyty do edycji obrazu poprzez zmianę układu obiektów tak, aby pasowały one do nowego opisu. Jeśli chodzi o skuteczność generowania obrazów w oparciu o opisy tekstowe, to 91% użytkowników uznawało nowy model za skuteczniejszy od dotychczas stosowanych. W ramach dalszych badań naukowcy chcieliby sprawdzić, jak model poradzi sobie z bardziej złożonymi obrazami, w których pojawią się liczne “zakłócenia”.
