
Czym w ogóle jest model językowy?
Model językowy to jeden z typów modeli sztucznej inteligencji i jest to program wytrenowany na dużych zbiorach tekstu, który przewiduje, co powinno pojawić się dalej w zdaniu. Jak to działa? Ano tak, że kiedy wysyłacie pytanie do “magicznego czatu”, model widzi je jako ciąg małych kawałków tekstu i podpowiada kolejny kawałek, potem następny i tak aż do momentu, aż powstanie odpowiedź. Im większy model, tym zwykle mądrzejsze podpowiedzi, ale tym więcej zasobów (pamięci i mocy) potrzeba, żeby go uruchomić.
Dzisiejsze modele to prawie zawsze transformatory, bo to akurat architektura, która potrafi “skupić uwagę” na najważniejszych fragmentach tekstu, zamiast przeliczać wszystko po kolei jak w starych sieciach. Dzięki temu transformer lepiej rozumie zależności w długich zdaniach i kontekst rozmowy.
Typy architektur modeli językowych
Współczesne modele językowe dzielą się na kilka rodzin, które różnią się sposobem kodowania wejścia i generowania wyjścia. Wybór architektury determinuje typowe zastosowania, wymagania pamięciowe oraz profil wydajności.
- Decoder-only – najczęściej stosowana architektura do generowania. Model otrzymuje cały dotychczasowy tekst w oknie kontekstu i za pomocą przyczynowej uwagi przewiduje kolejne tokeny krok po kroku. Typowe obszary użycia: dialog, kod, streszczenia, ogólne pisanie. Przykłady: GPT, Llama, Qwen, DeepSeek.
- Encoder-decoder – dwustopniowa konstrukcja, w której encoder tworzy reprezentację wejścia, a decoder generuje wyjście. Klasyczne zastosowania to tłumaczenia, podsumowania i zadania tekst-na-tekst wymagające bogatego, dwukierunkowego zakodowania wejścia. Przykłady: T5, FLAN-T5, mT5, BART, NLLB.
- Encoder-only – architektura ukierunkowana na reprezentację tekstu zamiast swobodnej generacji. Stosowana w wyszukiwaniu podobnych dokumentów, klasyfikacji, budowie embeddingów oraz jako retriever w systemach RAG. Generacja bywa możliwa metodami fill-mask, lecz nie jest naturalnym trybem pracy. Przykłady: BERT, RoBERTa, E5.
Do czatowania, asystentów, podsumowań i kodu stosuje się przeważnie architekturę decoder-only. W tłumaczeniach oraz klasycznych zadaniach seq2seq dominuje encoder-decoder. W embeddingach, klasyfikacji i RAG standardem jest encoder-only jako warstwa wyszukująca w parze z generatorem, najczęściej pracującym jako decoder-only.
Parametry modelu SI
Model składa się z parametrów, czyli liczb uczonych podczas treningu. Ich skala waha się od milionów do setek miliardów. Większa liczba parametrów zwykle koreluje z lepszym rozumowaniem i transferem wiedzy, ale podnosi koszty pamięci, energii i czasu obliczeń. Sam “licznik parametrów” nie przesądza jednak o jakości – istotne są również dane treningowe, liczba kroków, architektura warstw, jakość tokenizera i techniki regularyzacji.
Coraz częściej stosowana jest architektura MoE (Mixture of Experts). Oznacza to, że zamiast jednego “monolitu” model zawiera wiele specjalistycznych podmodułów, z których podczas generacji aktywuje się tylko niewielki podzbiór. Pozwala to zwiększać pojemność wiedzy bez liniowego wzrostu kosztu pojedynczej odpowiedzi. W praktyce rozróżnia się więc “parametry całkowite” (cała pojemność) i “parametry aktywne” na krok generacji (koszt obliczeniowy).
Tokeny – jednostki tekstu i ich koszt
Modele operują na tokenach, a więc najmniejszych jednostkach przetwarzania tekstu. Token nie musi być jednak całym słowem, bo np. w językach europejskich często jest częścią słowa lub znakiem interpunkcyjnym. Najpopularniejsze schematy podziału to BPE lub SentencePiece. Orientacyjnie 1 token odpowiada 3-4 znakom, ale zależy to od języka i konkretnego słownika.
Tutaj wchodzi też kwestia okna kontekstu, czyli maksymalnej liczby tokenów, które model może jednocześnie wziąć pod uwagę. Do tego limitu wliczają się wszystkie tokeny wejściowe oraz wszystkie tokeny wyjściowe. Zapis formalny jest prosty: liczba_tokenów_wejścia + liczba_tokenów_wyjścia ≤ rozmiar_okna_kontekstu. Jeśli limit wynosi 64 tys. tokenów, a wejście zajmuje 20 tys., to na odpowiedź pozostaje około 44 tys. tokenów. Jeśli wejście zużyje 60 tys., odpowiedź nie przekroczy mniej więcej 4 tys. tokenów. Limit dotyczy całej historii sesji, a nie tylko ostatniego pytania.
W oknie znajdują się: bieżący prompt, ewentualne dołączone dokumenty lub wyniki wyszukiwania RAG, systemowe instrukcje modelu oraz zachowana historia rozmowy, o ile nie została wcześniej zredukowana. W przypadku modeli multimodalnych do limitu liczą się także tokeny reprezentujące obrazy. Różne modele mają różne tokenizery, dlatego ten sam tekst może dać inną liczbę tokenów. Szacunek 1 token = 3-4 znaki jest tylko przybliżeniem zależnym od języka i słownika.
Po osiągnięciu limitu najstarsze fragmenty kontekstu są odcinane. Model przestaje widzieć tę część historii, co może prowadzić do utraty wcześniej ustalonych założeń, zmian stylu lub sprzeczności w długiej sesji. Technicznie rośnie bufor KV cache trzymający wewnętrzny stan warstw, a jego rozmiar skaluje się z długością sekwencji. Gdy superszybkiej pamięci dynamicznej zaczyna brakować, to system przy odpowiedniej konfiguracji ucieka do strategii typu offloading do RAM lub nawet SSD, co zwiększa opóźnienia i obniża tokeny na sekundę (tok/s).
Przy ustawianiu swojego modelu najprościej jest myśleć o budżecie tokenów na sesję. Jeśli w typowych zapytaniach planowany kontekst ma 48 tys. tokenów, a okno to 64 tys., to bezpieczny budżet odpowiedzi wynosi około 16 tys. tokenów. Warto jednocześnie uwzględnić narzut stałych elementów, takich jak instrukcja systemowa lub stały prefiks, które zajmują część budżetu niezależnie od długości pytania. Przy krótkich odpowiedziach wąskim gardłem bywa wczytanie długiego promptu, a z kolei przy krótkim poleceniu wąskim gardłem bywa sama generacja.
Kontekst, czyli krótkotrwała pamięć sesji
Kontekst to krótkotrwała pamięć modelu w trakcie sesji. Technicznie utrzymywany jest bufor KV cache, który przechowuje wektory kluczy i wartości dla kolejnych warstw. Dzięki temu przy generowaniu kolejnych tokenów nie dochodzi do ponownego przeliczania całej historii, co redukuje opóźnienia. Rozmiar KV cache rośnie liniowo wraz z długością kontekstu i liczbą warstw, dlatego sprzęt o dużej pojemności pamięci ma przewagę w długich rozmowach.

Istnieją techniki “wydłużania” skutecznego kontekstu, takie jak warianty skalowania pozycji (np. modyfikacje RoPE). Ich efektywność zależy jednak od konkretnego modelu, implementacji i ustawień. Sama stabilność i jakość przy bardzo długich kontekstach są funkcją zarówno architektury modelu, jak i przepustowości oraz pojemności pamięci w urządzeniu.
Kwantyzacja, czyli nieco mniejsza precyzja, ale większa użyteczność
Kwantyzacja modelu polega na zapisie wag, a czasem także aktywacji, w niższej precyzji liczbowej. Zamiast FP16 lub BF16 stosuje się FP8, FP6, FP4 albo INT8 i INT4. Efekt? Mniejsze zużycie pamięci i często wyższa szybkość, kosztem ryzyka utraty jakości w trudnych zadaniach, do których zalicza się precyzyjna matematyka, złożone programowanie czy długie rozumowanie.

Rozróżnia się kwantyzację tylko wag (weight-only) oraz wag z aktywacjami (W8A8, itp.). Ważne są też szczegóły, a w tym kwantyzacja per-kanał vs per-tensor, dobór skali, symetria rozkładów i ewentualna kalibracja. Dobrze dobrane ustawienia potrafią być “przezroczyste” w prostych zastosowaniach, a jednocześnie umożliwić uruchamianie większych modeli na sprzętach o ograniczonym rozmiarze pamięci. Sprzęt projektowany pod niskie precyzje w rdzeniach tensorowych ogranicza narzut obliczeniowy tej techniki.
Trzy drogi dopasowania swojego modelu SI
- Trening od zera
- Budowa modelu na czystych danych, z pełną kontrolą nad architekturą, tokenizacją i procedurą uczenia. Najbardziej kosztowna ścieżka – wymaga ogromnych zbiorów danych, długiego czasu i znacznych zasobów obliczeniowych. Jest stosowana głównie w dużych ośrodkach badawczo-rozwojowych.
- Fine tuning
- Dostrojenie gotowego modelu do konkretnego zadania lub stylu na mniejszym zbiorze przykładów. Najczęściej wykorzystuje metody PEFT (np. LoRA), które modyfikują tylko niewielki ułamek parametrów, zapisując różnice względem oryginalnych wag. Pozwala to szkolić na pojedynczej maszynie. W tej rodzinie mieszczą się także metody optymalizacji preferencji (DPO, ORPO), które dopasowują zachowanie modelu do wzorcowych odpowiedzi.
- RAG – Retrieval Augmented Generation‘
- Podejście, w którym wagi modelu pozostają niezmienione. System buduje indeks wektorowy dokumentów, wyszukuje najbardziej pasujące fragmenty do zapytania i dołącza je do kontekstu podczas generacji. RAG sprawdza się, gdy treści ulegają częstym zmianom, mają charakter wrażliwy lub wymagają ścisłego cytowania źródeł. Typowa implementacja łączy encoder-only jako warstwę wyszukującą z generatorem typu decoder-only.
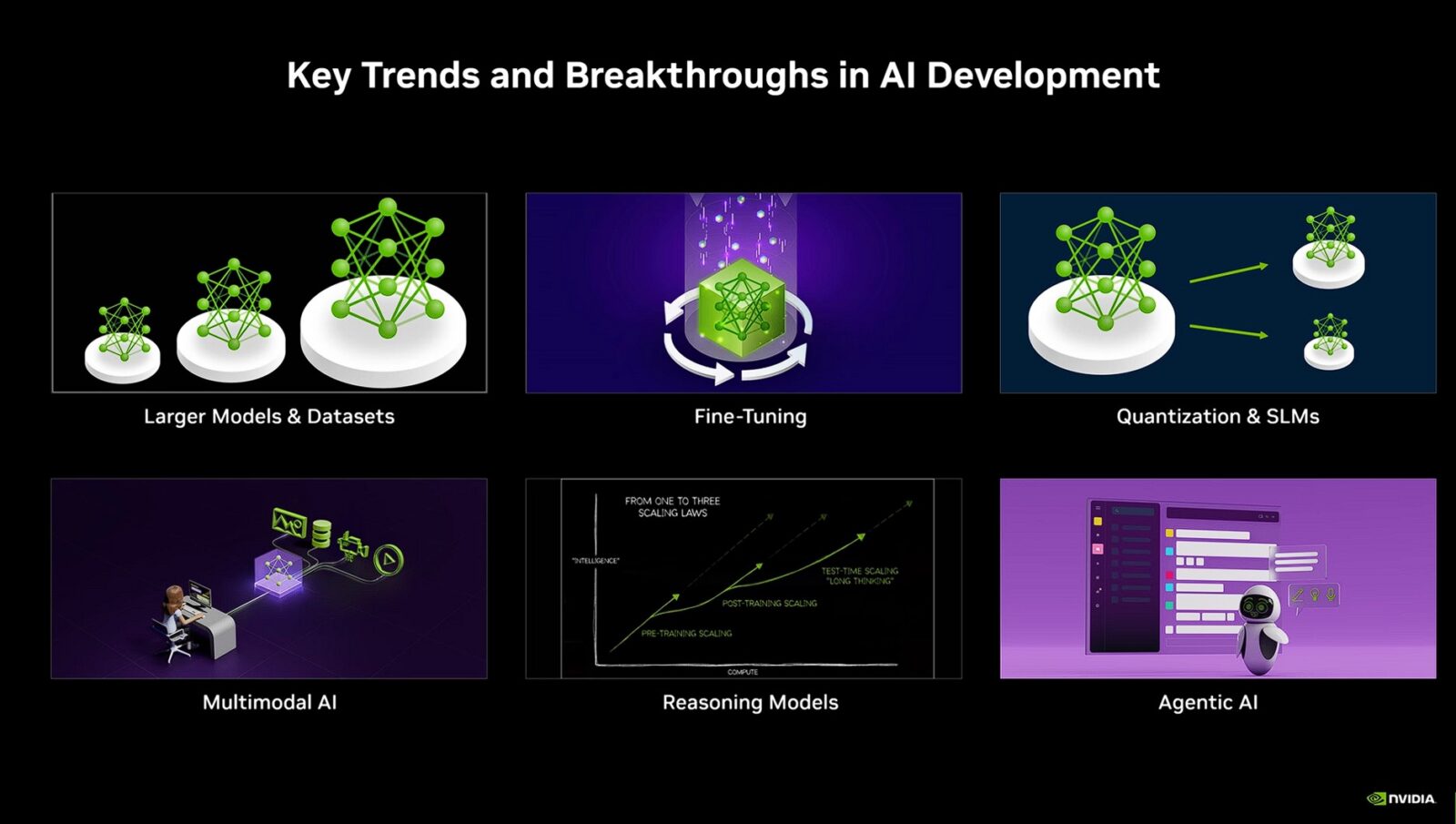
Jak odpowiada model sztucznej inteligencji?
Wiedząc już, że modele to tylko i wyłącznie sprytna matematyka, kolejnym kawałkiem potrzebnej wiedzy jest to, jak “pod maską” taki program udziela nam odpowiedzi. Najprostszy jego tryb to greedy search, w którym model zawsze wybiera najbardziej prawdopodobny następny token. Jest szybki i spójny, ale lubi się zapętlać i bywa nudny. Dlatego najczęściej włączamy losowe próbkowanie, które dopuszcza także mniej oczywiste tokeny i daje bardziej naturalny język.
Jednym z podstawowych parametrów generowania jest temperatura, która skaluje rozkład prawdopodobieństw i pośrednio wpływa na “ryzyko halucynacji”. Przy niskiej temperaturze (do 0,3) uzyskujecie mało losowości, odpowiedzi rzeczowe i przewidywalne, co jest dobre do kodu czy streszczeń. Wchodząc na poziom średni (0,4-0,7), uzyskujecie balans między trafnością a świeżością sformułowań, co stanowi podstawowe ustawienie do ogólnej rozmowy. Poziom wysoki (0,8+) to już ustawienie typowe do czegoś w rodzaju burzy mózgów i kreatywnego pisania, ale musimy pamiętać, im wyższa temperatura przy długich odpowiedziach, tym większe staje się ryzyko halucynacji.
Temperaturę uzupełniają filtry top-k oraz top-p, które to zawężają pulę rozważanych tokenów. Działa to tak, że top-k bierze tylko k najprawdopodobniejszych tokenów, a top-p dobiera najmniejszy zbiór tokenów o łącznym prawdopodobieństwie p. Można używać obu tych parametrów jednocześnie, ale często wystarcza top-p bez top-k (np. 0,9) albo umiarkowane wartości obu (np. top-p 0,95 i top-k 40-100) zależnie od zadania. Sprawa ma się podobnie z karami za powtórzenia, które przeciwdziałają zapętlaniu się modelu poprzez podnoszenie kosztu użycia niedawnych tokenów czy zniechęcanie do tokenów występujących w całym tekście przynajmniej raz lub po prostu często.

W skrócie? Podniesienie temperatury powoduje zwiększenie różnorodności odpowiedzi kosztem ścisłości. Z kolei zawężenie top-p lub zmniejszenie k podnosi kontrolę, ale może uciąć rzadkie, trafne formy. Kwestia powtarzania się modelu w odpowiedziach to również coś, co można dostosowywać wraz z codziennym korzystaniem z chatbota. Ważne jest to, aby przy niezadowalających wynikach unikać dopasowywania wszystkich parametrów jednocześnie. Najlepiej dokonywać regulacji pojedynczo, aby zmiany jednego parametru nie nałożyły się na siebie i doprowadziły do błędnych wniosków.
Sprzęt do lokalnej sztucznej inteligencji
Użyteczność końcowa sprzętu do zastosowań SI takiego jak np. NVIDIA DGX Spark zależy od tego, jaki model SI wybierzesz, jak go skwantyzujesz, czy dopasujesz go do własnych danych i finalnie jak napiszesz prompt. Sprzęt ma dostarczyć wyłącznie fundament, czyli wydajność, przekładającą się na szybkie wczytywanie długiego kontekstu, szybkie generowanie, stabilność pod obciążeniem czy niskie opóźnienia, a to wszystko przy sensownym koszcie energii. Dlatego też trzon testu tego typu sprzętu powinien opierać się przede wszystkim na surowych metrykach, żeby nie mylić jakości modelu z jakością samego urządzenia. Z racji jego niszowego charakteru ego segmentu, trudno jest dziś jednak o jakieś wymyślne porównania czy jednoznaczne testy, bo nie mamy odpowiednika np. zestawu testów 3DMark, jak to ma miejsce w przypadku tradycyjnych komputerów.
Co najważniejsze, posiadając DGX Spark i odpowiednio go konfigurując, możecie raz na zawsze zapomnieć o subskrybowaniu innych usług AI, jeśli korzystacie z nich w typowy, a nie jakiś wyspecjalizowany sposób. W takim układzie najważniejsze jest to, że cała praca modelu jest wykonywana lokalnie, więc nie musicie obawiać się o wycieki danych, czy konieczność posiadania dostępu do Internetu. Najlepsze jest to, że w takim trybie możecie doszkolić model na własnych danych, aby np. podrzucał kod w waszym stylu i oparciu o waszą architekturę oraz założenia, czy uruchomić go w trybie RAG i przeszukiwać np. pdf-y bez konieczności wysyłania ich np. do ChataGPT, który zresztą ma limit przesyłanych załączników na jedną odpowiedź.

Pamiętajcie jednak o jednym – dziś sprzęt do lokalnej sztucznej inteligencji i związany z nim ekosystem to nie coś tak łatwego w użytkowaniu, jak smartfon. Wymaga wiedzy, czasu, eksperymentów i testów, bo jeśli ot odpalicie na takim DGX Spark byle pierwszy lepszy model i będziecie oczekiwać jakości odpowiedzi na poziomie wykorzystywanego regularnie ChataGPT z płatną subskrypcją, to szybko się rozczarujecie.
