W dalszej części tekstu przybliżymy szczegóły budowy nowych układów, wyjaśnimy pojęcia, takie jak shader, ROP czy jednostka teksturowania, i zademonstrujemy, dlaczego nowoczesne procesory graficzne w niektórych zastosowaniach deklasują najwydajniejsze procesory Intela i AMD.
Podstawy: budowa karty graficznej
Współczesne karty graficzne zwykle składają się z pięciu komponentów: interfejsu systemowego, pamięci graficznej, procesora graficznego GPU (Graphics Processing Unit), bufora ramki i tzw. RAMDAC (Random Access Digital/Analog Converter).
Interfejs systemowy znajduje się najbliżej płyty głównej. Obecnie stosuje się złącze PCI Express. Za jego pośrednictwem nieobrobione dane są ładowane do pamięci graficznej, w której przechowywane są wszelkie obiekty graficzne i tekstury. Jej pojemność waha się od 256 do nawet 2048 MB. Informacje są następnie odczytywane przez procesor graficzny, który przygotowuje do wyświetlenia na ekranie pozycje, ruchy i fakturę wszelkich obiektów widocznych w trójwymiarowej scenie. Po obróbce gotowy obraz jest umieszczany w buforze klatek i wędruje do RAMDAC – układu, który przetwarza cyfrowe obrazy, nadając im formę analogową, odpowiednią dla wyjścia VGA, lub przesyła je do cyfrowych wyjść DVI, HDMI lub DisplayPort.
Potok graficzny: droga obrazu
Większość elementów karty graficznej odgrywa wyłącznie rolę pomocniczą. Najważniejszy jest procesor grafiki. Kiedy docierają do niego dane, rozpoczynają się obliczenia, których efekt możemy zobaczyć na monitorze. Potok graficzny, czyli droga, jaką pokonują dane w karcie graficznej: od interfejsu do bufora klatek, jest podobny we wszystkich nowoczesnych urządzeniach.

Potok graficzny – jak powstaje scena 3D
Cała sekwencja powtarzana jest w wypadku każdej pojedynczej klatki. Aby wyświetlany ruch był płynny, ludzkie oko musi wychwycić co najmniej 25 klatek na sekundę. W nowoczesnych grach komputerowych największy realizm uzyskuje się dopiero przy 60 klatkach na sekundę – procesor graficzny ma więc dużo pracy.
Pierwszy etap potoku graficznego to obliczenia wstępne i przekształcenie informacji przez procesor wstępny (tzw. Setup Engine lub Input Assembler). Ten ostatni rozpoznaje typ danych, tj. bada, czy ma do czynienia z wektorami, obrazami, czy też kodem programu, i odpowiednio przygotowuje informacje do dalszej obróbki. Jest też ustalane, czy grafika będzie przetwarzana przez układ cieniowania wierzchołków (Vertex Shader), geometrii (Geometric Shader) lub pikseli (Pixel Shader), czy też przez jednostkę teksturowania.
Każdy obiekt trójwymiarowy składa się z trójkątów. Ich współrzędne są wykorzystywane przez układ cieniowania wierzchołków do tworzenia modeli przestrzennych przedstawianych brył. Są one ustawiane w odniesieniu do punktu widzenia wirtualnego obserwatora. Przyjęte pole widzenia określa się mianem bryły widzenia. Po uszeregowaniu struktur w przestrzeni sprawdza się, czy określony obiekt układu znajduje się w bryle widzenia, tzn. czy jest widoczny, czy też częściowo lub całkowicie zasłonięty przez inne obiekty. Aby uniknąć wykonywania niepotrzebnych obliczeń, niewidoczne elementy są ze sceny usuwane – proces ten nazywa się obcinaniem bryłowym. Z kolei jeśli obiekt jest usuwany, gdyż znajduje się zbyt daleko od obserwatora, by ten mógł go zauważyć, albo zbyt blisko niego czy za nim, mówimy o tzw. clippingu.
Ostatnim etapem pracy układu cieniowania wierzchołkowego jest odpowiednie oświetlenie trójwymiarowej sceny. W tym celu w wymodelowanej przestrzeni umieszczone zostaje jedno lub więcej źródeł światła – bez tego utonęlibyśmy w ciemności.

Porównanie kart Nvidii i ATI
Vertex Shader może jedynie manipulować istniejącymi obiektami, nie ma natomiast możliwości dodawania nowych elementów, takich jak punkty, linie i trójkąty. W celu zaspokojenia takich potrzeb w wydanym w listopadzie 2006 roku pakiecie DirectX 10 znalazł się układ geometrii. Może on tworzyć zupełnie nowe formy geometryczne, dzięki czemu np. wirtualne drzewa będą rosnąć. Shader geometryczny uruchamiany jest po utworzeniu trójwymiarowej sceny.
Kiedy obraz, który powinien być widziany przez obserwatora, jest przygotowany w formie siatki zawierającej źródła światła, powstaje jego dwuwymiarowe odwzorowanie, które może być wyświetlone na monitorze. Proces ten nazywamy renderowaniem albo rasteryzacją. Każdy punkt dowolnego obiektu trójwymiarowego, dotychczas zapisany w formie wektorowej, jest przekształcany w piksel. Następnie układ przechodzi do obliczeń związanych z cieniowaniem wykonanych przez shader pikseli. Nadaje on kolejnym punktom kolor oraz inne cechy, jak przezroczystość, odbijanie światła lub faktura. W ten sposób zostaje oddana barwa wyświetlanych elementów. Kolejne zadania wykonywane przez shadery można jeszcze raz prześledzić na infografice.
Obraz jest już prawie gotowy – pozostaje tylko subtelna obróbka polegająca na nałożeniu nań różnorodnych filtrów, by uczynić go jeszcze bardziej realistycznym. Używa się do tego tekstur, a więc gotowych map bitowych, które nakłada się na bryły jak tapetę (jest to tzw. mapowanie tekstur).
W efekcie powstają obrazy realistyczne jak fotografie, jednak bez cech charakterystycznych dla obiektów trójwymiarowych. Oznacza to, że pokryte teksturą drzewa pięknie wyglądają od frontu, ale z boku są zupełnie płaskie. Zadanie filtrowania anizotropowego polega na tym, by tekstury obiektów przedstawionych w perspektywie widziane z pewnej odległości nadal były ostre.
Po zakończeniu mapowania w jednostkach teksturowania klatka wędruje do komponentu ROP (Raster Operations Processor – procesor operacji rastrowych; ATI używa określenia Render Back-End – render końcowy). Podczas rasteryzacji obraz jest powiększany, w wyniku czego na krawędziach tworzy się coś w rodzaju stopni. Temu efektowi zapobiega antyaliasing, który rozpoznaje “schodki” na obrazach i je wygładza.
Gotowy obraz zostaje przeniesiony do bufora ramek. Tu kończy się potok graficzny. W kolejnej części artykułu opisujemy różnice techniczne między topowymi modelami obu czołowych producentów.
GPU: serce karty graficznej
Podstawowe założenia dotyczące projektowania nowych architektur procesorów graficznych są definiowane przede wszystkim przez DirectX 10. Jest to zbiór interfejsów programowych wykorzystywanych przez gry w systemie Windows Vista. Wcześniejsze konstrukcje, opisane przy okazji potoku graficznego, rozróżniały jednostki obliczeniowe ALU (Arithmetic Logic Unit – arytmetyczna jednostka logiczna) pracujące jako shadery pikselowe lub shadery wierzchołkowe. DirectX 10 wprowadza zupełnie nowy rodzaj shadera: tzw. united shader, czyli shader jednolity. Dzięki temu wszystkie jednostki obliczeniowe wchodzące w skład procesora graficznego mogą, zależnie od aktualnych potrzeb, pracować jako shadery pikselowe, wierzchołkowe lub geometryczne. Obecnie zarówno ATI, jak i Nvidia oferują wyłącznie układy zgodne z DirectX 10. Nowe chipy umożliwiają znacznie lepsze wykorzystanie pojedynczych jednostek obliczeniowych. O to, by dane były prawidłowo rozdzielane pomiędzy wolne jednostki, dba rozdzielacz wątków, który analizuje strumienie danych przygotowane przez procesor wstępny, segreguje je, a także przydziela zadania poszczególnym ALU.
Procesory graficzne ATI i Nvidii różnią się głównie strukturą wewnętrzną – szczególnie architekturą shaderów jednolitych, zwanych też procesorami strumieniowymi (SP, stream processor). W chipach Nvidii mieści się do 240 takich struktur, za to ATI upakowuje ich w jednym układzie aż 800. Gdy jednak porównamy możliwości jednostek obu producentów, różnica przestaje być tak wyraźna. Procesory strumieniowe Nvidii są jednowymiarowe i jako jednostki skalarne (obliczające wartość jednego z elementów: czerwień, zieleń, błękit albo wartość alfa) mogą podczas jednego taktu przeprowadzić zarówno operację typu MADD (dodawania i mnożenia) w obliczeniach związanych z cieniowaniem, jak i operację typu MUL (mnożenia) w obliczeniach dodatkowych. Shadery jednolite ATI mogą w tym czasie wykonać wyłącznie operację MADD. Aby uzyskać odpowiednią wydajność, łączy się 5 shaderów w jedną pięciowymiarową jednostkę wektorową, tworząc w ten sposób rdzeń cieniowania o mocy zbliżonej do mocy jednego procesora strumieniowego Nvidii.
Obu konkurentów różnią jednak nie tylko możliwości pojedynczego procesora strumieniowego, ale też sposób, w jaki są one podzielone i pogrupowane na chipie. ATI łączy pięć procesorów w jeden rdzeń cieniowania, co przy 800 procesorach daje 160 rdzeni. W kartach z serii ATI Radeon HD 4800 każde 16 rdzeni cieniowania tworzy jedno jądro SIMD. Pojedyncze jądro może w jednym takcie przeprowadzić takie same obliczenia na wielu danych naraz (z zastrzeżeniem, że operacje nie mogą się od siebie różnić). Każde jądro SIMD ma 16 kB własnej pamięci, pozwalającej na szybką wymianę informacji między procesorami strumieniowymi. Oprócz tego należy do niego: klaster teksturowania złożony z 4 procesorów teksturowania, dekompresor, jednostka adresowania, sampler oraz jednostka filtrowania, a ponadto pamięć cache L1 przeznaczona do tymczasowego przechowywania tekstur. Rdzenie wchodzące w skład jądra porozumiewają się poprzez szynę żądania danych, wykorzystując globalną pamięć podręczną liczącą kolejne 16 kB. Dodatkowo w GPU mieszczą się cztery bloki pamięci cache L2 bezpośrednio połączone z główną pamięcią graficzną i wymieniające informacje z rdzeniami SIMD poprzez odpowiedni łącznik. Element zwany UTDP (wielowątkowy procesor wysyłający) dzieli strumienie informacji pochodzące z procesora wstępnego między shadery: wierzchołkowy, pikselowy i geometryczny. Dba też o odpowiednie wykorzystanie jednostek obliczeniowych.
Pod względem liczby procesorów strumieniowych wygrywa ATI, co jednak Nvidia nadrabia zwiększoną liczbą procesorów operacji rastrowych (ROP). Procesor GT200 oferuje ich 32, RV770 – tylko 16. Nvidia przoduje również, jeśli chodzi o pojemność pamięci graficznej i jej interfejs komunikacyjny: GT200 obsługuje pamięć o pojemności 1024 MB, korzystając z pasma o szerokości 512 bitów. W kartach ATI montuje się też 1024 MB pamięci RAM, ale obsługiwanej przez interfejs 256-bitowy. W modelu Radeon HD 4870 ATI stawia jednak na moduły nowej generacji GDDR5 o dwukrotnie większej przepustowości (4 Gb/s w stosunku do 2 Gb/s) i zużywające o 1/4 mniej energii elektrycznej niż starsze pamięci GDDR3 nadal stosowane przez Nvidię.
GPGPU: procesor graficzny wyprzedza CPU
Możliwości GPU nie ograniczają się jedynie do grafiki 3D. To już druga generacja procesorów graficznych, w których umieszczono elementy ALU mogące pracować jako potężne jednostki przeliczania równoległego.
W niektórych zastosowaniach, np. symulacjach finansowych, karty graficzne uzyskują wyniki nawet 150 razy szybciej niż procesory CPU. Pozwalają na to shadery dające się dowolnie programować. Czynią one z chipów graficznych tzw. GPU ogólnego przeznaczenia (GPGPU, General Purpose GPU).
Uzyskiwana wydajność jest ogromna – GT200 osiąga do 933 GFLOPS, a RV770 nawet 1200 GFLOPS. W porównaniu z tymi wartościami wydajność procesora Intel Core 2 Quad Q6600, wynosząca 22,4 GFLOPS, wydaje się bardzo mała. Należy jednak pamiętać, że nie wszystkie programy mogą być podzielone na wątki. Dlatego do zastosowań ogólnych bardziej odpowiednie są standardowe procesory CPU, które z kolei, jeśli chodzi o specjalistyczne obliczenia, np. symulacyjne, zostaną w tyle za każdą jednostką GPU.
Do tej pory problem stanowiła implementacja programów do obsługi przez procesory graficzne. Nvidia opracowała jednak technologię CUDA (Compute Unified Device Architecture), której elementem jest środowisko programistyczne języków C i C++. Umożliwia ona tworzenie podzielnych na wątki aplikacji i ich wykonywanie przez jednostki GPU. ATI rozwija podobny projekt o nazwie CTM (Close to the Metal), pozbawiony jednak wygodnego środowiska C++.
Największą wadą procesorów GPU w porównaniu z CPU było do tej pory to, że liczby zmiennoprzecinkowe mogły być obliczane jedynie w przybliżeniu do 32 bitów. Skomplikowane obliczenia, podczas których pojawiają się wysokie wyniki pośrednie, wymagają dwukrotnie większej dokładności – 64 bitów. ATI i Nvidia rozwinęły jednak produkcję chipów graficznych zapewniających odpowiednią precyzję przetwarzania liczb zmiennoprzecinkowych. Producenci mikroprocesorów CPU powinni szykować się do obrony swoich pozycji.
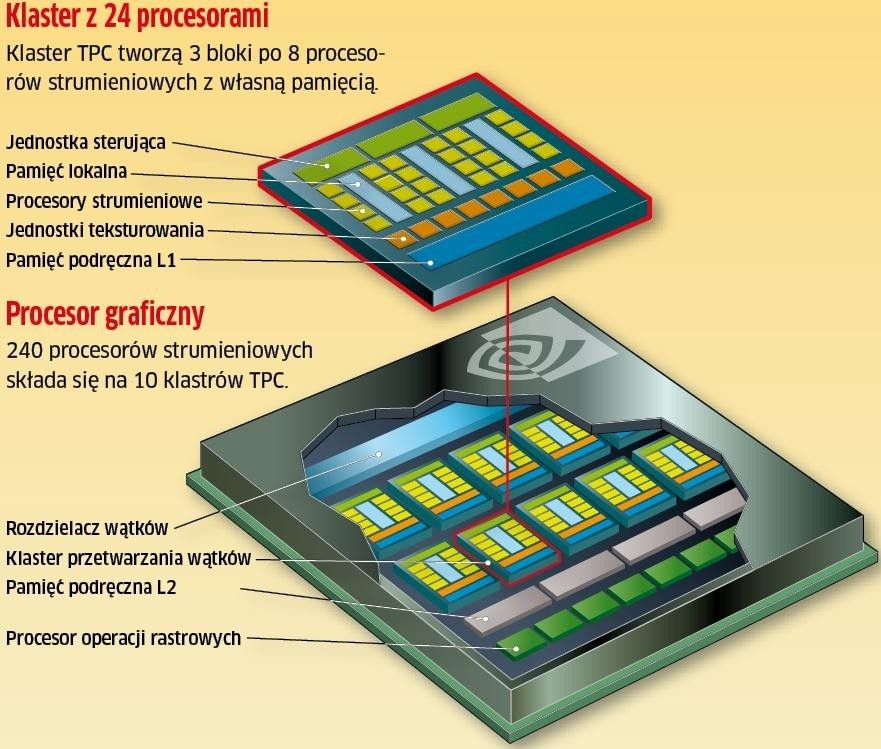
Procesor graficzny Nvidia GT200
GT200 to sztandarowy produkt Nvidii. Ma pozwolić firmie na zachowanie palmy pierwszeństwa w zakresie wydajności oraz zostawić daleko w tyle konkurentów w klasie high-end.
Na najnowszą architekturę procesorów graficznych składa się wiele komponentów – przede wszystkim tzw. shadery jednolite, inaczej procesory strumieniowe. W wyścigu triumfuje Nvidia, umieszczając w swoim produkcie aż 240 takich jednostek. Są one podzielone na bloki liczące 8 sztuk, które z kolei tworzą trójki, tzw. klastry przetwarzania wątków. Taka architektura pozwala na wykonywanie zarówno operacji graficznych, jak i obliczeń równoległych.
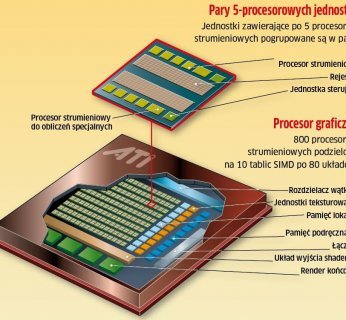
Procesor graficzny ATI RV770
Wprowadzając na rynek model RV770, ATI zrobiło krok naprzód. Po latach posuchy firma córka koncernu AMD odbierze Nvidii wielu klientów korzystających z urządzeń ze średniej półki (500–1000 zł).
ATI również pracuje nad wykorzystaniem kart graficznych do przeprowadzania obliczeń równoległych. W tym celu firma zapakowała w jednym układzie aż 800 procesorów strumieniowych. Procesory te pogrupowane są po 5 sztuk (do każdej takiej “piątki” dochodzą rejestry i jednostka sterująca). Architektura ta ma zapewniać wydajność rzędu 1200 GFLOPS – znacznie więcej niż 933 GFLOPS uzyskiwanych przez procesory Nvidii.


Słowniczek
Antyaliasing: Na ostrych krawędziach pojawiają się “stopnie”. Antyaliasing je niweluje.
Bufor ramek: Tworzone są w nim klatki obrazu wyjściowego. Aby na monitor trafiały dopiero w pełni gotowe obrazy, stosuje się najczęściej dwa lub więcej buforów.
Bufor Z: Decyduje, które elementy sceny 3D mają być rysowane przez procesor, a które nie, ponieważ są zasłonięte przez inne bryły.
Filtrowanie anizotropowe: Dzięki filtrowaniu anizotropowemu również oddalone obiekty są wyraźne.
RAMDAC: Przygotowuje obraz do wyświetlenia na ekranie z wykorzystaniem gniazda D-Sub, DVI, HDMI lub Display Port.
Raster Operation Procesor (ROP): Znajdują się w nich filtry, takie jak antyaliasing czy filtr anizotropowy.
Shader pikselowy: Barwa każdego pojedynczego piksela jest ustalana przez shader pikselowy.
Shader wierzchołkowy i geometryczny: Szkielet sceny 3D jest tworzony przez shadery wierzchołkowe i geometryczne.
Tekstury: By uzyskany został realistyczny wygląd, powierzchnie obiektów 3D są pokrywane teksturami.

