

Standardem dla płyt HD staje się Blu-ray, coraz mocniej wypierający DVD. Dla niebieskiego krążka przewidziano 3 kodeki, ale i na tym polu H.264 pobił konkurentów – VC-1 Microsoftu pozostaje zjawiskiem marginesowym, zaś MPEG-2 przepadł z kretesem. Podobnie rzecz ma się z kamerami. Nawet DivX w wersji 7 przesiada się na H.264. Co więcej, są duże szanse na to, że jeszcze w tym roku H.264 będzie masowo stosowany w sprzętowych odtwarzaczach BD.
Podstawy: Jak działają kodeki wideo
H.264 nie wynalazł kodowania wideo na nowo. Zasadniczo działa tak samo jak MPEG-2: film to nic innego jak obrazy (ramki) odtwarzane w tempie – w zależności od standardu – pomiędzy 24 a 30 razami na sekundę. Kodek MPEG-2 grupuje ten strumień w tzw. GOP-y (Group of Pictures), zwykle po 12 klatek dla każdej sekundy.
Pierwszy obraz każdego GOP-a to Intra-Frame (I-Frame). Kodek kompresuje ją jako specyficzny JPEG. W tym celu dzieli ramkę na makrobloki o wielkości 16×16 pikseli, a następnie w przypadku każdego przeprowadza konwersję do przestrzeni kolorów YCrCb, zapisując piksele w postaci: (Y, Cb, Cr), gdzie Y oznacza luminancję (jasność), a dwie pozostałe są składowymi koloru niebieskiego (b) oraz czerwonego (r). Wydzielone wartości łączy się na nowo. Ponieważ oko ludzkie lepiej postrzega drobne zmiany jasności niż kolorów, ta pierwsza ma wyższy priorytet i zostaje przepisana bez strat, czyli jako makroblok 16×16. W obydwu kanałach barw odrzuca się natomiast wartość co drugiego piksela, więc do ich opisu wystarczą dwie matryce 8×8 albo jedna 16×8. Otrzymane wartości są przekształcane w dziedzinę częstotliwości, która opisuje, jak mocno składowe jasności i obydwu kolorów zmieniają się w makrobloku. W procesie kwantyzacji odrzuca się następnie najrzadziej występujące ekstrema.
Pozostałe ramki w GOP-ie to tak zwane Inter-Frame’y. Kodek tworzy je na podstawie I-Frame’a za pomocą wektorów ruchu (Motion Estimation). Inter-Frame’y są dwojakiego rodzaju i inaczej się je koduje: makrobloki w P-Frame’ach (Predictive) wykorzystują I-Frame albo poprzednią P-Frame jako obraz odniesienia; B-Frame’y (Bi-Predictive) używają do tego celu zarówno poprzednich, jak i następnych I- albo P-Frame’ów.
Zaletą B-Frame’ów jest to, że mogą opisywać za pomocą wektorów ruchu części obrazów, które wywodzą się również z ramek następujących po nich. W efekcie B-Frame’y zajmują najmniej miejsca ze wszystkich ramek. Co to oznacza? Im więcej B-Frame’ów w kodowanym filmie, tym mniejsza będzie jego wynikowa wielkość.
Tak jak w przypadku I-Frame’ów, kodek zapamiętuje w makroblokach P- i B-Frame’ów oprócz wektorów ruchu również częstotliwości. Ale nie jako wartości absolutne, lecz różnicowe, w stosunku do bloku odniesienia, z którego wektor ruchu został wyprowadzony.
Transformacja: Mniejsze bloki to wyższa jakość
Dotąd pisaliśmy wyłącznie o wspólnych cechach kodeków MPEG-2 i H.264. Jednak gdy mowa o szczegółach, pojawiają się podstawowe różnice dotyczące transformacji w dziedzinę częstotliwości. Kodek MPEG-2 dzieli makrobloki na bloki o wielkości 8×8, na których przeprowadza następnie dyskretną transformację cosinusową (DTC). Reguła podziału jest następująca: dominujące obszary obrazu opisują niskie częstotliwości, a detale – wysokie.
Po transformacji blok zostaje posortowany na nowo, jako macierz współczynników DC. Wartość z jej lewego górnego rogu opisuje zarówno najniższą częstotliwość, jak i przeciętną jasność bloku. Ponieważ istnieje duże podobieństwo pomiędzy leżącymi obok siebie współczynnikami DC, kodek zapamiętuje je nie jako wartości absolutne, lecz jako różnicę w stosunku do poprzednika. Pozostałe współczynniki sortowane są tak, że w kierunku na prawo i w dół umieszcza się te odpowiadające coraz wyższym częstotliwościom, które kodują całe bogactwo detali. Powód? Przy wysokich częstotliwościach oko gorzej rozróżnia niuanse jasności i kolorów, więc ich wartości dają się bardziej zaokrąglać bez straty jakości.
H.264 odżegnuje się od zaokrągleń stosowanych w DC i stosuje transformację całkowitą (Integer Transformation) na blokach 4×4, a przy lepszej jakości 8×8. Przesiadka na transformację 4×4 jest konieczna, ponieważ w przeciwieństwie do MPEG-2, H.264 potrafi kodować z jej użyciem również Intra- i Inter-Frame’y. Przewaga mniejszych bloków uwidacznia się, gdy w określonej części ramki kwantyzacja odcina zbyt wiele informacji o obrazie. Przesiadka ma jeszcze inną zaletę: transformacja całkowita stosowana w H.264 pozwala na dokładniejsze odtworzenie podziału częstotliwości niż DCT.
Kwantyzacja: Elastyczne wielkości
Właściwa redukcja danych odbywa się w następnym kroku: chodzi o kwantyzację. W najlepszym przypadku kodek dopasowuje wartości częstotliwości do wymagań ludzkiego postrzegania – niskie zapamiętuje, a większość wysokich usuwa ze strumienia danych. W tym celu na każdy blok nakłada macierz kwantyzacji.
Kodek MPEG-2 dzieli przy tym poszczególne wartości częstotliwości przez odpowiadające jej parametry macierzy. Po drodze często gubi się przez to najwyższe częstotliwości. Inaczej jest w przypadku H.264, który nie dzieli wartości, lecz zastępuje tę operację dodawaniem i odejmowaniem macierzowym. Ma to tę zaletę, że podczas tego procesu w H.264 nie występują błędy zaokrągleń. Dla parametrów kwantyzacji H.264 ma aż 51 stopni. Nie zwiększają się one jednak liniowo, jak w MPEG-2, lecz logarytmicznie. To oznacza, że dla niskich częstotliwości są one dokładniejsze niż dla wysokich – co bardziej odpowiada postrzeganiu ludzkiego oka.
Ponieważ H.264 obsługuje zarówno bloki o wielkości 8×8, jak i 4×4, potrzebuje dla każdego z tych rozwiązań macierzy kwantyzacji. W sumie musi mieć ich aż cztery, ponieważ używa innych do Intra-Frame’ów, a innych do Inter-Frame’ów. Powód? Wartości różnicowe Inter-Frame’ów dają się mocniej kompresować. Stąd parametry kwantyzacji są w nich dużo wyższe niż w Intra-Frame’ach.
Standardowa macierz H.264 sama w sobie zapewnia dobre wyniki nawet przy mocno zróżnicowanych szybkościach przepływu danych. Ale doświadczony użytkownik może zastosować własną macierz, która sprawdzi się nawet w przypadku tak wysokich transferów, do jakich dochodzi w Blu-rayu. Zostanie ona zapamiętana w kodowanym filmie, aby dekoder mógł ją wykorzystać podczas odtwarzania, stosując poprawną kwantyzację odwrotną. Należy jednak pamiętać, że niestandardowa kwantyzacja odgrywa istotną rolę w redukcji danych. Jeśli kodek w odtwarzaczu nie będzie umiał jej prawidłowo odtworzyć, jakość obrazu może znacznie się pogorszyć.
I-Frame’y: Efektywniejsza kompresja
Kodek MPEG-2 po przeprowadzeniu DCT i kwantyzacji kończy pracę nad I-Frame’em. H.264 stosuje dodatkowo predykcję przestrzenną (Spatial Prediction), która jeszcze mocniej kompresuje ramki. Podobnie jak współczynniki DC związane z MPEG-2 albo JPEG, wszystkie wartości opisuje się w tym przypadku jako różnice pomiędzy sąsiednimi blokami. Ponieważ kodek zaczyna pracę od lewego górnego rogu każdej ramki, umiejscowione tam i przetworzone już makrobloki stają się odniesieniem dla pozostałych.
W wypadku bardzo mało zróżnicowanych fragmentów obrazu składowe jasności i kolorów są często prawie identyczne. Wówczas kodek może wyprowadzić wartości bloków pochodzące od jego bezpośrednich lewych albo górnych sąsiadów. W wyniku kwantyzacji otrzymywane są prawie same zera, które idealnie dają się ścieśniać. Ale nawet gdy składowe jasności i kolorów różnią się pomiędzy blokami, zapis różnicowy sprawia, że otrzymane liczby niewiele odstają od zera, przez co mogą być znacznie efektywniej kompresowane niż wartości absolutne. Dla predykcji przestrzennej bogatych w detale Intra-Frame’ów H.264 przewiduje zmienne wielkości makrobloków – kodek może wybierać pomiędzy rozmiarami 16×16, 8×8 i 4×4.
Kodowanie: Więcej możliwości upakowania
Podczas kodowania Inter-Frame’ów chodzi o to, żeby możliwie jak najwięcej makrobloków każdej ramki opisać za pomocą wektorów ruchu. Środkiem do tego jest elastyczne traktowanie każdej z nich. Z P- i B-Frame’ami H.264 pracuje tak samo jak MPEG-2, ale bez sztywnej struktury GOP-ów. Kodek może wywieść B-Frame’a z innego B-Frame’a. Potrafi wyprowadzić także wektory ruchu jednej ramki z makrobloków kilku innych ramek (Multi Frame Prediction). Tak dzieje się w profilu Blu-ray freeware’owego kodeka x264 – 3 ramki odniesienia, jak również komercyjnego MainConcept-Encoder, który używa aż po 4 ramki. Takich technik nie przewidziano w MPEG-2.
Ponieważ makroblok P-Frame’a daje się wyprowadzić z P-Frame’ów ostatniego I-Frame’a, H.264 wymyślił i zastosował zupełnie nowy typ ramki, IDR-Frame. Chodzi o I-Frame’a, w przypadku którego nie wolno odnieść następujących bezpośrednio po nim P- i B-Frame’ów do ramki, która chronologicznie znajduje się przed nimi. Wykorzystuje to na przykład kodek x264, który wkłada IDR-Frame’a przeciętnie co 250, 300 ramek, a więc w przedziałach 10-sekundowych. Jednak IDR-Frame’ów nie przeznaczono do umieszczania w stałych interwałach, lecz w określonych momentach – idealna chwila to dla przykładu zmiana sceny. Dlatego jeśli program do obróbki wideo importuje strumień wideo bezpośrednio z kamery (AVCHD-Stream), nie może go bez nagrywania pociąć inaczej niż tylko w miejscach IDR-Frame’ów. Dokładniej się nie da.
Przetwarzając Inter-Frame’y, H.264 stosuje dodatkowo różne wielkości makrobloków. Zakres identyczny jak w przypadku Intra-Frame’ów: od 16×16 do 4×4, ale dopuszczalne są inne formy, np. 16×8 albo 8×4. Jako że do każdego bloku przypisuje się jeden wektor ruchu (przy B-Frame’ach możliwe są dwa), kodek może za pomocą zmiennej wielkości bloków i zwielokrotnionych ramek odniesienia lepiej nadzorować drobne szczegóły obrazu i opisywać więcej treści, używając wektorów. Chodzi o to, że wektory ruchu zapewniają dokładność do jednej czwartej piksela, podczas gdy w wypadku MPEG-2 – tylko do jednej drugiej.
Tryb bezpośredni: Kopiowanie wektorów ruchu
Pojęcie wektora ruchu jest właściwie mylące, ponieważ nie opisuje on ruchu, lecz jedynie wskazuje na inny blok w sąsiedniej ramce. Ogólnie rzecz biorąc, wektor składa się z trzech wartości: dwóch współrzędnych przestrzennych oraz listy numerów ramek odniesienia. Z powodu Multi Frame Prediction kodek H.264 potrzebuje również takiej listy (List0) do każdego bloku w P-Framie.
W przypadku B-Frame’ów metoda jest bardziej skomplikowana, ponieważ tutaj dozwolone są nawet dwa wektory dla jednego bloku. Aby temu sprostać, kodek stosuje dwie listy. List0 zaczyna się od ostatniej ramki i posuwa się do tyłu w czasie, List1 zaczyna się od kolejnej ramki i idzie do przodu. Istnieją cztery tryby reprezentacji wektorów w B-Framie: jedna ramka odniesienia z List0 lub z List1 i Bi-Predictive, dwie bezpośrednie (Direct Mode) oraz predykcja ważona.
W trybie B-Predictive kodek adresuje po jednym bloku odniesienia z ramek z List0 albo List1, a następnie wartości z obydwu bloków uśrednia i wylicza na tej podstawie ramkę różnicową.
W trybie bezpośrednim kodek musi zapamiętywać jedynie numery ramek odniesienia, bez konieczności zapisu wektorów ruchu. W Temporal Direct Mode kolejny blok dziedziczy wektory ruchu bloku mające w ramce odniesienia te same współrzędne przestrzenne. Podczas odtwarzania dekoder musi wyliczyć wyłącznie odstęp czasowy pomiędzy ramkami. W Spatial Direct Mode blok po prostu każdorazowo przejmuje wektory ruchu pochodzące z sąsiednich bloków.
Nowa w H.264 jest predykcja ważona (Weighted Prediction). Za jej pomocą do każdego bloku odniesienia można dołączyć dodatkowy czynnik opisujący zmiany jasności i kolorów. To oszczędza miejsce, np. przy rozjaśnieniach albo ściemnieniach, ponieważ treść obrazu pozostaje taka sama – zmienia się tylko jasność. Z tego powodu predykcja ważona świetnie sprawdza się w przypadku przenikania obrazów, gdzie adresuje się bloki odniesienia znajdujące się zarówno przed, jak i po ramce odniesienia.
Jednak najwięcej miejsca kodek oszczędza dzięki opuszczanym (Skipped) makroblokom w P- i B-Frame’ach, których treść po prostu pobiera z poprzednich ramek. Bloków tego typu kodek używa najczęściej w statycznych scenach albo ujęciach, w których drugi plan przez dłuższy czas pozostaje bez zmian.
Deblocking-Filter: Obraz wolny od błędów
W przypadku niskich wartości przepływu kodek musi sięgać do wysokich parametrów kwantyzacji – wiele liczb zostaje wyzerowanych i praktycznie zostaje po jednej wartości na każdy kanał koloru i jasność. W efekcie w kodowanej ramce powstają identyczne bloki, choć w oryginalnym filmie widać w ich miejscu znacznie więcej detali. Ta cecha, niestety, negatywnie wpływa na satysfakcję użytkownika z oglądania filmu.
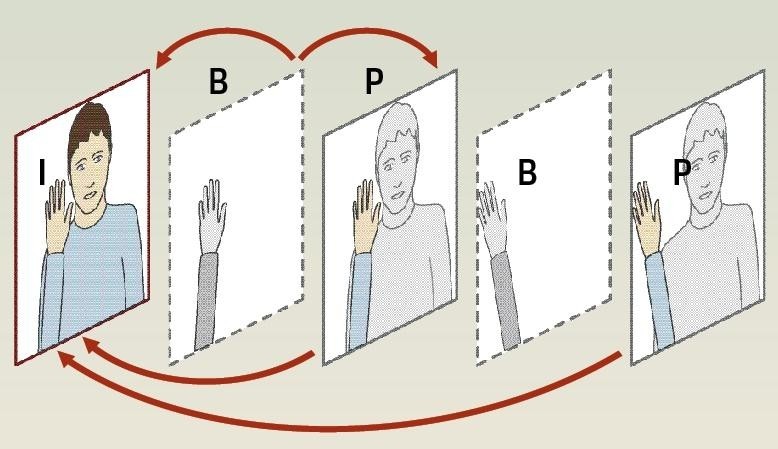
W przeciwieństwie do MPEG-2 kodek H.264 potrafi zmierzyć się z tym zjawiskiem, za pomocą Deblocking Filter. Stosuje go dekoder podczas odtwarzania filmu, dopasowując jego siłę do faktycznego stanu transmisji: przy niskich parametrach kwantyzacji filtr działa słabiej albo w ogóle się wyłącza, natomiast przy wysokich parametrach kwantyzacji jego oddziaływanie się wzmaga. Deblocking Filter odgrywa też pewną rolę w kodowaniu (patrz infografika): wiele ramek służy jako odniesienie dla innych. Dlatego kodek używa filtra, zanim wykorzysta daną ramkę, aby na jej podstawie wyliczyć wektory ruchu dla następnej.
Użytkownik może ustawić w filtrze dwa najważniejsze parametry: wartość Alpha określa, jak intensywnie filtr będzie stosowany podczas odtwarzania; wartość Beta reguluje detekcję bloków opisującą, od którego momentu filtr będzie identyfikował szczegół obrazu jako oddzielny blok, a nie wydzielony obiekt. Dopiero gdy zapewniona jest wystarczająca szybkość transmisji – jak np. w przypadku Blu-raya – opłaca się osłabić działanie filtra. Dzięki temu udaje się zachować więcej szczegółów.
RDO: Dodatkowa kontrola jakości
H.264 podczas pracy musi podejmować decyzje, które mają wpływ na końcowy rezultat, czyli skompresowany film. Już na etapie wyboru rozmiaru bloków B-Frame’a pojawia się wiele kombinacji dla konkretnych makrobloków. Od tego wyboru zależą też czynniki, takie jak liczba wektorów ruchu i ramek odniesienia.
Rate-Distortion Optimization (RDO) jest odpowiedzialna w tym procesie za jakość: wylicza, czy wybór, dzięki któremu podwyższona zostanie potencjalna możliwość kompresji, ale prowadzący do strat jakości obrazu, jest rzeczywiście konieczny. I na odwrót: RDO musi zdecydować, czy konkretne ustawienie podnoszące jakość nie zajmie zbyt wiele miejsca w kodowanym strumieniu. Kodek musi trzymać się wytyczonych przez RDO reguł dotyczących wielkości pliku wynikowego albo innych parametrów, jak np. przepływności 40 Mb/s podczas kodowania płyty Blu-ray.
Nakładka RDO orientuje się w jakości obrazu dzięki PSNR (Peak Signal to Noise Ratio), który matematycznie opisuje różnicę pomiędzy kodowaną ramką a pierwowzorem. RDO pilnuje wprawdzie zgodności z oryginałem, ale nic nie mówi o subiektywnych wrażeniach wzrokowych. A właśnie one są najważniejsze. Dlatego kodek ma również inne mechanizmy korekcyjne do dyspozycji, nawet gdy nie są one częścią standardu: zarówno w darmowy x264, jaki i w MainConcept wbudowano np. Adaptive Quantization (AQ). H.264 kompresuje bowiem niektóre motywy za mocno, np. ciemne sceny albo niebieskie niebo. Kodek upraszcza delikatne gradacje kolorów, co prowadzi do tzw. bandingu – bardzo dużych i widocznych pasów jednolitej barwy. AQ próbuje temu zaradzić, redukując parametry kwantyzacji w odpowiednich blokach. Ale to oznacza, że trzeba im przydzielić większe pasmo przepływu danych.
Podobny mechanizm zastosowano też w x264. PsyRDO, bo o nim mowa, to metoda psychowizualna, oceniająca, czy drobne zawirowanie w obrazie przeszkadza oku czy nie. Chodzi o to, żeby zachować w ramkach więcej szczegółów nawet kosztem błędów w budowie bloków. Ludzkiemu oku taki obraz wydaje się bardziej naturalny niż taki, w którym nie występują widoczne błędy, ale brak w nim detali.
CABAC: Lepsze upakowanie
Kodowanie entropijne to bezstratny, niezależny od medium proces kompresji. Zazwyczaj kodeki stosują je podczas upychania danych w końcowym strumieniu. Ale H.264 ma i tu coś nowego do zaoferowania. W profilu Baseline – podstawowym – H.264 ogranicza się do optymalizacji zmiennej CAVLC (Context-Adaptive Variable Length Coding) – nadzorującej proces kompresji ZIP przewidziany dla filmów. Lepsze wyniki zapewnia CABAC (Context-based Adaptive Binary Arithmetic Coding), która wymaga jednak więcej mocy obliczeniowej. H.264 wbudował ją w profil High.
Kodek wykonuje pracę w 3 następujących krokach: w pierwszym binaryzacja zamienia skwantyzowane liczby w ciąg zer i jedynek. W drugim kroku kodek dopasowuje do powstałego ciągu odpowiedni model prawdopodobieństwa – do wyboru ma ich ponad 400. W trzecim na podstawie ciągów binarnych i wybranego modelu stochastycznego kodek wylicza bit za bitem, z jakim prawdopodobieństwem w strumieniu wyjściowym pojawi się 0 albo 1.
CABAC kompresuje średnio o 15 proc. lepiej niż CAVLC. Efektywność podnosi się znacznie, gdy pojawiające się kolejno wartości są identyczne. Cała maestria kodeka wideo polega więc na tym, aby wytworzyć możliwie wiele takich samych wartości jasności i barw w obszarze częstotliwości albo – za pomocą wektorów ruchu – dużo wartości leżących bardzo blisko zera. Prócz tego musi on zredukować złożoność oryginalnego strumienia, ale tak, żeby nie odbiło się zbytnio na jakości. W najlepszym możliwym przypadku widz nie powinien dopatrzyć się różnicy. Ze wszystkich kodeków wideo obecnie najlepiej radzi sobie z tym właśnie H.264.
Popularne kodeki
X264 Opensource’owy kodek jest szybki i zapewnia wysoką jakość obrazu. Dzięki predefiniowanym profilom dla Blu-raya i urządzeń przenośnych nie ma żadnych problemów z kompatybilnością.
Cena: darmowy
Info: www.videolan.org/developersMAINCONCEPT Kodek stosowany jest w wielu programach do montażu wideo, np.takich jak Adobe Premiere. Wyróżnia go wysoka kompatybilność sprzętowa. Jakość obrazu zbliżona do tego, co oferuje x264.
Cena: ok. 300 euro
Info: mainconcept.comDIVX 7 Od wersji 7 także DivX przesiadł się na H.264. Kodek bazuje na MainConcept, ale obsługuje tylko profil High Level 4.0, przez co bez przeróbek nie jest kompatybilny z formatem BD.
Cena: ok. 15 euro
Info: www.divx.comNero W Nero znajduje się francuski kodek Ateme, który tworzy filmy o dobrej jakości, ale pracuje nieco wolniej niż MainConcept.
Cena: ok. 30 euro
Info: www.nero.comQUICKTIME PRO Kodek Apple’a jest ograniczony i nadaje się co najwyżej do korzystania z profilu Baseline. Przetwarza maksymalnie dwa B-Frame’y, brakuje mu transformacji 8×8 z profilu High.
Cena: 30 euro
Info: apple.com
Profile i poziomy: Standardy zgodne z kodowaniem H.264
Standard H.264 dzieli się na różne profile i poziomy, które określają, jakie cechy kodeka zostaną wykorzystane, a jakie nie. Najważniejsze profile to podstawowy (Baseline), Main oraz High. Profil podstawowy znajduje zastosowanie w klipach internetowych i na urządzeniach przenośnych, takich jak iPhone czy PSP. Zoptymalizowano go pod kątem odtwarzania na sprzęcie o niskiej wydajności, przez co nie wspiera on ważnych technologii takich jak B-Frame’y. Profil Main wykorzystuje się także w YouTubie, ale tylko do odtwarzania wideo o rozdzielczości 720p (720 linii w pionie bez przeplotu). Profil High wkracza do akcji w przypadku Blu-raya. Jest także wykorzystywany przez kamery HD, nagrywające w formacie AVCHD. Profil zapewnia optymalną jakość obrazu i obsługuje prawie pełną paletę funkcji H.264.
Strumienie kompatybilne z Blu-rayem
Prócz profili w standardzie H.264 definiuje się też poziomy, które oferują szybkości przesyłu danych od 4 do 25 Mb/s. Blu-ray używa profilu 4.1, ale kodeki, które go obsługują, nie są jeszcze z nim w pełni kompatybilne. Dodatkowo muszą one bowiem obsługiwać Decoded Picture Buffer (DPB) – specyficzną funkcję skalowanych strumieni wideo, która wymaga użycia dużej ilości pamięci. x264 oferuje bufor 40 000 kb. Sony stosuje w swoim Blu-rayu tylko 30 000 kb. Wielkość DPB musi być tak dobrana, żeby mogła przechować wszystkie ramki odniesienia. W odtwarzaczach programowych nie ma z tym problemu, inaczej niż w sprzętowych, gdzie ilość pamięci jest niezbyt wielka.
Problemy z X.264
Wiele filmów przygotowanych za pomocą kodeka x.264 w trybie 1080p (pionowa rozdzielczość 1080 linii, bez przeplotu) przeznaczonych do odtwarzaczy BD (Blu-ray Disk) początkowo nie uruchamiało się na nich, ponieważ kodek ustawiał zbyt wysoką wartość DPB w strumieniu wideo. Z upływem czasu pojawił się odpowiedni profil (BD-Profil) dla x264, który zastosowano w konwerterze MeGUI (sourceforge.net/projects/megui). Ale x264 ma jeszcze problem z poleceniem »b-pyramid«, które pozwala na wyprowadzanie B-Frame’ów z innych B-Frame’ów. A to oznacza, że trzeba pamiętać wiele ramek – zbyt wiele dla ustawionej wartości DPB. Skutek: odtwarzacze BD nie potrafią odtworzyć takiego filmu. Aby zatem utrzymać kompatybilność, użytkownicy nie powinni używać polecenia »b-pyramid« w x264, dopóki nie pojawi się odpowiednia łata.
HDTV – Łaty do nagrywania
Nagrania HDTV często są wystawiane w Sieci jako filmy 720p (pionowa rozdzielczość 720 linii, bez przeplotu) skompresowane kodekiem x264. Nie są one kompatybilne ze standardem Blu-ray, ponieważ mają zapisane w nagłówku informacje o zastosowanej regule profilu 5.1. x264 używa jej automatycznie, gdy kodek bierze pod uwagę wyłącznie jakość obrazu. Aby odtwarzacz BD odtworzył taki strumień, użytkownik musi za pomocą narzędzia takiego jak H264Info (sourceforge.net/projects/batchccews) podmienić nagłówek na pasujący do profilu 4.1. Po tym zabiegu strumień da się również zapisać w formacie BD. B-Pyramid nie odgrywa tu żadnej roli, ponieważ ramki 720p są mniejsze, w związku z czym nie przekraczają maksymalnej wartości DPB.
Profile H.264 Baseline Main High Makrobloki typu: I- / P- / B- +/+/- +/+/+ +/+/+ Więcej ramek odniesienia + + + Filtr Deblocking + + + Kodownie entropijne: CAVLC/CABAC +/- +/+ +/+ Kodowanie przeplotu – + + Przestrzeń kolorów: 4:0:0 / 4:2:0/ 4:2:2 -/+/- -/+/- +/+/- Głębokość próbkowania w bitach: 8 / 9 / 10 +/-/- +/-/- +/+/+ Bloki transformacji: 4×4 / 8×8 +/- +/- +/+ Niestandardowa macierz kwantyzacji – + +
Transformata cosinusowa
Najważniejsze przekształcenie w kompresji obrazów to dyskretna transformata cosinusowa (DTC), która przenosi kanały jasności i kolorów bloku w dziedzinę częstotliwości. Po transformacji bloki zawierają nie wartości pikseli, ale ich uogólnione uśrednienia zwane współczynnikami DC. Na przykład blok składowej niebieskiej, w lewym górnym rogu zapisuje wartość proporcjonalną do średniej zawartości tego koloru w całym bloku pikseli. Kolejne punkty przechowują średnie dla coraz wyższych częstotliwości, którą można tu interpretować jako zmienność danej składowej na obszarze bloku. Zaletą DTC jest to, że wraz ze wzrostem częstotliwości współczynniki DC zmniejszają się do tego stopnia, że w procesie kwantyzacji można je pominąć bez większych strat dla kodowanego obrazu, co pozwala na znaczną redukcją strumienia danych.