Stan obecny: Maszyny nie potrafią odczytywać danych z Sieci
W Internecie znajdują się ogromne zasoby informacji. Formy ich prezentacji zaprojektowali ludzie w sposób czytelny dla innych ludzi. Czytający może łatwo zrozumieć przekaz umieszczony na stronie i powiązać go z innymi danymi w Sieci. Niestety, maszyny ciągle tego nie potrafią. To największa różnica między nami i jednocześnie największa trudność dla algorytmów próbujących wyłuskać sensowne informacje z sieciowego oceanu danych.
Dlatego współczesne silniki wyszukiwarek Google czy Yahoo przedstawiają nam jedynie posegregowaną listę poszukiwanych fraz uzyskaną za pomocą metod statystycznych. Tylko czy rzeczywiście o to nam chodzi? Niestety, prawie nigdy nie! Zdobywanie niezbędnych informacji wiąże się więc zwykle z pracochłonnym otwieraniem kolejnych stron z listy prezentowanych wyników, z których większość w ogóle nie zawiera potrzebnych nam danych. Przykład: w przypadku frazy “syrenka” w wynikach wyszukiwania znajdą się zarówno odnośniki do stron o Warszawie, jak i o starych samochodach czy baśniach Andersena. Dzieje się tak, ponieważ tym, czego potrzebujemy, jest wyszukiwanie oparte nie na słowach kluczowych, lecz na ich jednostkach znaczeniowych. Chodzi więc o semantykę. A tę system może zrozumieć, bazując na modelu przechowywania stron wykorzystującym ich strukturę.
Jest i inna przeszkoda w rozumieniu i przetwarzaniu zapytań: informacje w Internecie przechowywane są dziś w tak wielu formach, że bezpośrednie ich porównywanie okazuje się prawie niemożliwe. W rezultacie trudno jest je skondensować i zaprezentować w ujednoliconej, strawnej dla maszyn postaci. Jeśli dla przykładu poszukujemy informacji na temat Sieci semantycznej i taką frazę (“Sieć semantyczna”) wpiszemy, w wynikach wyszukiwania znajdziesz strony, których treść się pokrywa, uzupełnia lub wzajemnie sobie przeczy. Na nasze pytanie nie otrzymujemy więc jednoznacznej odpowiedzi, lecz jedynie zbiór prawdopodobnych wariantów.
A przecież na razie nasze rozważania dotyczą prostych zapytań. Co jeśli poprosimy Google albo Yahoo, żeby ustosunkowały się do frazy: “Ile lat ma Lech Kaczyński”? Otrzymamy odpowiedzi, które prawie zawsze będą wymagać dodatkowych wyszukiwań i obróbki skojarzeniowej. Najlepszym rozwiązaniem w tym przypadku będzie przekształcenie struktury zapytania – do postaci “Lech Kaczyński data urodzenia” – i poszperanie w wynikach. Ale dlaczego szperać mamy my, a nie boty sieciowe?
Rozwiązania: Organizacja zawartości Sieci i jej powiązanie
Terminem “sieci semantycznej” określana jest idea takiego gromadzenia informacji w Internecie, aby komputery mogły je przetwarzać ze zrozumieniem. Żeby było to możliwe, oprócz samych danych sieć semantyczna musi zawierać także dodatkowe informacje o relacjach pomiędzy nimi. Umieszcza się je w formie tekstowej, jako tzw. metadane.
Organizacja W3C, ustanawiająca standardy pisania stron WWW, opracowała już szereg otwartych schematów zapisu metadanych. Języki komputerowe, takie jak XML, RDF (Schemat), OWL i SPARQL, uzupełniając się wzajemnie, odgrywają tu bardzo istotną rolę. Umożliwiają bowiem zapis informacji o ontologii i taksonomii danych uporządkowanej semantycznie. Przykładowo dzięki SPARQL mamy w pełni rozwinięty język zapytań do uzyskiwania wyników z ontologii RDF. Więcej na ten temat w akapicie “Standardy i języki”.
Współczesne metody: Trzy drogi do Sieci semantycznej
Jak zmienić Sieć bazującą na dokumencie w Sieć rozumiejącą jego zawartość? Pierwszym krokiem w tym kierunku jest inny sposób gromadzenia informacji w Internecie – należy ją przechowywać w usystematyzowanych strukturach. Od strony technicznej nie wydaje się to trudne, bo istnieje wiele niezależnych dyscyplin, w których wiedza jest gromadzona w sposób uporządkowany od początku ich istnienia. Ale co zrobić z rozległymi zasobami informacji, które obecnie opierają się na dokumencie?
Programiści próbują do tego celu wykorzystać sztuczną inteligencję oraz lingwistykę komputerową. Termin NLU (Natural Language Processing – przetwarzanie języka naturalnego) obejmuje m.in. metody rozbioru wypowiadanych tekstów, tak jak czyni to człowiek: analizowane frazy są zwykle rozkładane na pojedyncze zdania. Jeśli zastosuje się wiedzę o strukturze zdania (podmiot – predykat – obiekt), semantyczny podział treści wydaje się łatwy. Dzięki temu w procesie przeszukiwania można identyfikować osoby, obiekty oraz zdarzenia i tworzyć powiązania między nimi, co znacznie zredukuje liczbę błędnych rezultatów na liście wyników. Przykład tego podejścia – od ogółu do szczegółu – został dokładniej opisany w akapicie “Aplikacje”.
Inne podejście do tej metody jest znane pod nazwą Microformats (microformats.org) i w czerwcu tego roku świętuje swoje czwarte urodziny. Jest to idea manualnego rozszerzania istniejących stron opartych na (X)HTML o specjalne elementy tego standardu, które uczynią owe strony czytelnymi dla komputerów. Dla przykładu znane platformy, takie jak Facebook, Flickr, Google Maps czy Yahoo, używają specjalnych, uniwersalnych schematów do przechowywania informacji o kontaktach, planach i zakładkach.
Ideę wbudowania informacji czytelnej dla innych komputerów w konwencjonalne strony oparte na (X)HTML popiera także W3C, ale chodzi tu o różne podejścia. Projektanci z Microformats kierują się zasadą polegającą na tym, aby potrzebne wyniki otrzymywać przy najmniejszym nakładzie pracy. Tymczasem W3C spełnia ten wymóg przez rozwijanie specyfikacji RDF. Pozwala ona na tworzenie ogólnych struktur, które mogą zostać wykorzystane do integracji metadanych. Niestety, to podejście wymaga większych nakładów pracy podczas tworzenia aplikacji. Z drugiej strony RDF jest bardziej ogólny i elastyczny, przez co w dalszej perspektywie może wyprzeć rozwiązanie Microformats.
Standardy i języki: Właściwe narzędzia dla programistów
Której specyfikacji należy używać do efektywnego tworzenia inteligentnych stron przyszłości? Poniżej przedstawiamy zestaw ważnych narzędzi programistycznych, a także narzędzi do tworzenia zapytań.
EXTENSIBLE MARKUP LANGUAGE (XML)
Podstawowym standardem w przypadku inteligentnych stron jest język oparty na znacznikach – XML. Umożliwia on zarówno zapis uporządkowanych informacji, jak i opis innych języków bazujących na znacznikach. Jednym z języków opartych na znacznikach jest XHTML, czyli bazująca na formacie XML wersja HTML. Standardy RDF i OWL, które umożliwiają tworzenie dokumentów z uporządkowanymi strukturami, także wykorzystują składnię XML.
RESOURCE DESCRIPTION FRAMEWORK
RDF jest językiem opisu dla ustrukturyzowanej informacji. Nie służy on jednak poprawnej prezentacji zawartości strony w przeglądarce, jak czyni to HTML. Podstawowym zadaniem RDF jest umożliwienie automatycznego przetwarzania danych ze strony, którą opisuje, oraz poprawne powiązanie jej z innymi informacjami w Sieci.
Dokument RDF jest opisywany przez graf skierowany. Zawiera on zbiór wierzchołków oraz krawędzi, które graficznie przedstawiane są jako strzałki. Każdy wierzchołek i każda krawędź mają własny identyfikator, Uniform Resource Identifier (URI). Ten ciąg znaków wskazuje abstrakcyjne lub fizyczne źródło danych i ma prostą składnię: »Schemat: Specyfika schematu«. W praktyce URI może być adresem strony takim jak www.chip.pl lub adresem email, np. mailto:[email protected]. Jednak URI może być całkowicie niezależny od stron WWW i używany tylko jako mechanizm do tworzenia jednoznacznej identyfikacji pojęć. Dlatego zwykle w dokumentach RDF, URI nie odnosi się do istniejących stron WWW.
Graf RDF może zostać w całości opisany poprzez specyfikacje jego krawędzi. Każda odnosi się do jednego elementu z trójki: podmiot – predykat – obiekt. To umożliwia opisanie tej struktury za pomocą skryptu bazującego na XML, który obecnie jest najczęściej wykorzystywany podczas tworzenia i przygotowywania ustrukturyzowanej informacji – choć nie jest jedyny. Istnieje też specyfikacja zwana Turtle, ale używa się jej raczej sporadycznie.
Z kolei RDF(S), gdzie “S” oznacza schemat, reprezentuje znaczące rozszerzenie standardu RDF i pozwala na specyfikacje danych z zakresu wiedzy terminologicznej lub schematów. Najpierw RDF umożliwia opisanie obiektu i jego relacji z innymi obiektami. Następnie za pomocą RDF(S) przypisujemy ten obiekt do danej klasy. Klasa ta z kolei może stać się klasą podrzędną lub nadrzędną dla jednej lub wielu innych klas. W rezultacie stosunkowo łatwo uzyskujemy reprezentację hierarchii klas. Jej przykładem może być taksonomia w biologii. W takim ujęciu istotne jest to, że obiekt jest nie tylko instancją danej klasy, ale również instancją wszystkich klas nadrzędnych w stosunku do niej – patrz ramka o taksonomii i przykład z listingu 1.
Inne rozszerzenie, “Property”, stworzono z myślą o właściwościach obiektu. Cecha taka jak “jestSzczęśliwieŻonaty” może być znowu podrzędną w stosunku do jednej lub wielu innych właściwości, jak na przykład “jestŻonatyZ”. W przypadku właściwości definicje pól, jak również ich wartości mogą być ograniczone do danej klasy. Przykładowo ograniczenie pól »osoba« w dwu klasach jest rozwiązaniem praktycznym. W tym celu zasoby muszą zostać sklasyfikowane jako »osoby«. Słownik RDF(S) zawiera znacznik »rdf: Statement« będący wskaźnikiem klasy służącym do modelowania deklaracji. Może on zostać użyty do przypisania obiektu do danej deklaracji. Dzięki temu powiązaniu zdanie “Maciej twierdzi, że wszystkie ptaki są niebieskie” może zostać zarchiwizowane zgodnie z deklaracją, a nie jako generalnie poprawne twierdzenie.
WEB ONTOLOGY LANGUAGE (OWL)
Podstawą technologii OWL (w zasadzie powinno być WOL, ale skrót został zamieniony na OWL, co w języku angielskim oznacza sowę) są własności i klasy, jak w przypadku RDF(S), który opisaliśmy, przedstawiając wystąpienie instancji klasy. Jednakże OWL pozwala na tworzenie złożonych relacji pomiędzy tymi klasami i własnościami. Ponadto klasy mogą być deklarowane jako rozłączne lub identyczne. Można je zamknąć i określić, które indywidualne przypadki należą do danej klasy. Większość operacji »łączenie«, »cięcie« i »uzupełnianie« daje później możliwość oczyszczenia systemu. Wystąpienia klas mogą być ograniczane lub wyłączane poprzez ograniczenia ról. Dyrektywy związane z ograniczeniem liczby wystąpień, takie jak »co najmniej jeden«, »wszystkie«, »co najmniej X«, »co najwyżej Y« pozwalają na dalsze sterowanie uzyskiwanymi wynikami.
OWL występuje w trzech odmianach: OWL Lite, OWL DL i OWL Full. Każda z nich bazuje na poprzedniej. Ostatnia zapewnia największą swobodę w tworzeniu wyrażeń opisujących zawartość strony. Niestety, przyczyniła się ona do wzrostu trudności semantycznych, co doprowadziło do powstania odmian OWL DL i OWL Lite. OWL DL opiera się na koncepcji, która nie rodziła problemów. W związku z tym jest prawie w całości wspierana przez istniejące aplikacje (patrz akapit “Aplikacje” – Protégé, Pellet, KAON2). OWL Lite oferuje tylko najważniejsze elementy języka i z tego powodu ma relatywnie mniejsze znaczenie w praktyce.
SIMPLE PROTOCOL AND RDF QUERY LANGUAGE (SPARQL)
Jak uzyskać informacje ze struktur opisanych powyżej? W tym celu w RDF-ie zawarty został SPARQL – nowo utworzony standard do tworzenia zapytań o dane z RDF oraz prezentujący ich wyniki. Zapytanie SPARQL składa się z trzech podstawowych części. »PREFIX« zawiera informacje o przestrzeni nazw, »SELECT« jest używany do formatowania wyświetlanych wyników, »WHERE« do określenia ograniczeń danego zapytania. Umożliwia to weryfikację wartości właściwości (patrz listing 2). Dzięki temu możliwe jest wyszukiwanie obiektów, które zawierają określone wartości właściwości. Poza tym wyniki posortujemy za pomocą dyrektywy »SORTED BY«, a wykorzystując dyrektywę »OFFSET«, ograniczymy liczbę prezentowanych wyników.
Do tej pory W3C nie zdefiniowało jeszcze języka zapytań dla OWL. Skłania się jednak do dostosowania SPARQL tak, aby można go było również używać w przypadku zapytań o dane z ontologii OWL. W przeciwieństwie do standardu RDF, OWL DL oferuje jako część samego języka wyrażenia, które mogą być użyte do wyszukania określonych instancji zgodnie z danymi zawartymi w opisie klasy. Do obsługi innych zapytań z OWL DL, szczególnie koniunkcji, stosowane są na razie podstawowe formy SPARQL.
RESOURCE DESCRIPTION FRAMEWORK IN ATTRIBUTES (RDFa)
Standard RDFa, tak jak Microformats, jest stosowany w celu uzupełniania istniejących stron (X)HTML o metadane. RDFa używa do tego przestrzeni nazw i ich słowników, które wiążą ze sobą informacje. W 1994 roku Dublin Core Metadata Initiative (dublincore.org) opublikowało Dublin Core (DC). Był to często używany słownik, za pomocą którego zapisywało się informacje o dokumentach, takie jak autor, tytuł czy data utworzenia. W tej chwili w RDFa stosowane jest wyrażenie »xmlns:dc«, które wskazuje na przestrzeń nazw Dublin Core.
Dyrektywa »dc:title« jest obecnie krótką formą wyrażenia »purl.org/dc/elements/1.1/« i określa tytuł dokumentu, a »dc:creator« – jego autora. Informacje te można również przedstawić w RDF: (document, dc:title, title) oraz (document, dc:creator, author). Inna dyrektywa, »about«, wskazuje położenie elementu na serwerze. Przykładowo można uzupełnić informacje dotyczące obrazka na stronie o tytuł i nazwę autora (patrz listing 3). Inny przykład to przestrzeń nazw Friend-of-a-Friend (FOAF), która oferuje słownik umożliwiający opisywanie informacji dotyczących kontaktów: wyrażenie »typeof« przypisuje elementowi HTML określony typ, a dyrektywy »foaf:name«, »foaf:mbox« i »foaf:phone« identyfikują dane dotyczące kontaktu w formacie, który nadaje się do przetwarzania automatycznego (patrz listing 4).
Aplikacje: Edytory semantyczne i wyszukiwarki
Jak tworzyć ontologie i których narzędzi używać? Najbardziej znany edytor ontologii to Protégé (protege.stanford.edu). Za pomocą tego opensource’owego narzędzia możemy tworzyć i rozwijać ontologię, dokonywać jej wizualizacji, eksportować ją czy przypisywać poszczególne obiekty do klas. Z kolei automaty wnioskujące, takie jak Pellet (clarkparsia.com/pellet) czy KAON2 (kaon2.semanticweb.org), pozwalają na tworzenie deklaracji klas pochodnych z ontologii OWL. Pellet jest również dostępny w ramach licencji Open Source, natomiast KAON2 może być bezpłatnie używany wyłącznie do zastosowań niekomercyjnych.
Edytory ontologii i automaty wnioskujące tworzą podstawę serii aplikacji niezbędnych do tworzenia sieci semantycznych. Dla przykładu serwer Freebase (www.free-base.com) stworzony przez Metaweb Technologies służy temu, aby uporządkowana strukturalnie informacja z popularnych źródeł internetowych była tak samo łatwo dostępna dla automatów, jak dla ludzi.
Freebase zaczął od przetworzenia artykułów z dobrze znanych baz danych, jak Wikipedia czy MusicBrainz (musicbrainz.org). Serwery były analizowane pod kątem ich zawartości, którą następnie dodano do ontologii. W efekcie Freebase zawiera dane o ponad trzech milionach obiektów, 750 tys. osób, 450 tys. miejsc, 50 tys. firm i 40 tys. filmów. Jednakże Freebase używa własnej ontologii i własnego języka zapytań, który różni się od SPARQL.
Otwartą bazą opartą na RDF jest DBpedia (dbpedia.org). Jej podstawę również stanowią artykuły z Wikipedii. Obecnie zawiera ona 2,5 miliona obiektów w tym 108 tys. osób, 392 tys. miejsc, 57 tys. albumów muzycznych i 36 tys. filmów. Co więcej, możemy pobierać te dane, korzystając z SPARQL.
Z drugiej strony powstało już mnóstwo narzędzi, które potrafią wyszukiwać informacje w sposób kontekstowy. Dla przykładu wyszukiwarka semantyczna Powerset (www.powerset.com) łączy zawartość z dwóch źródeł wiedzy. Używa w tym celu semantycznie przygotowanych artykułów z Wikipedii oraz coraz częściej z Freebase, którą potrafią już analizować automaty. Aktualnie Powerset umożliwia tworzenie zapytań w języku naturalnym. W tym przypadku możliwe jest uzyskanie informacji zależnej od relacji pomiędzy interesującymi nas faktami. W efekcie tego na przykład w odpowiedzi na pytanie o wiek naszego prezydenta: “how old is jarosław kaczyński”, otrzymamy wynik “June 18, 1949 (59 years ago)” wraz z listą dokumentów, w których rezultat ten został odnaleziony.
Wyszukiwarka semantyczna Knowledge (www.trueknowledge.com) również podaje te same wyniki i z wyglądu jest bardzo podobna do Powerset. Ma jednak znacznie lepsze możliwości przetwarzania języka naturalnego. Możemy na przykład zapytać, czy Barack Obama jest starszy niż Hillary Clinton: “is barack obama older than hillary clinton” – otrzymamy odpowiedź, że nie (patrz listing 5).
Innym przykładem analizy według zasady “od ogółu do szczegółu” jest rozwiązanie firmy Open Calais. Jej przeglądarka Document Viewer (opencalais.com/Doc-Viewer) przeszukuje konwencjonalne dokumenty w Internecie w poszukiwaniu linii zawierających wystąpienia interesujących nas obiektów, faktów czy zdarzeń i ekstrahuje je – w postaci danych w formacie RDF. Gnosis (addons.mozilla.org/fire-fox/3999) to wtyczka do Firefoksa, która demonstruje możliwości tej witryny.
Perspektywy: Semantyczna Sieć jest i zostanie
Semantyczna Sieć dostarcza zestaw rozwiązań, umożliwiających efektywne wyszukiwanie informacji i zintegrowanie wyników pochodzących z różnych źródeł. Utworzone już zostały standardy opisu danych. Istnieją także metody, które pozwalają na korzystanie z tak precyzyjnych źródeł wiedzy. Choć stron WWW ze strukturalnie opisaną zawartością jest ciągle za mało, semantyczna analiza już istniejących zasobów i rozszerzenie ich treści o metadane w standardzie RDFa pokazują, że stworzenie inteligentnej Sieci przyszłości jest możliwe – proces już się rozpoczął. Pierwszym krokiem było przetworzenie zawartości pochodzącej z baz danych, takich jak Wikipedia czy MusicBrainz.
Należy jednak pamiętać, że Sieć semantyczna może działać tylko, jeśli zapewniony będzie dostęp do bardzo zróżnicowanych treści. Co więcej, zawartość stron WWW musi być łatwa do znalezienia i połączenia, a relacje między danymi lepiej opisane. Można jednak założyć, że rewolucja polegająca na przejściu od szukania fraz w wyszukiwarkach typu Google czy Yahoo do odpowiedzi na pytania zadane w języku naturalnym dokona się w najbliższych latach.
Co to jest W3C?
W 1989 roku pracujący wówczas w centrum badawczym CERN Tim Berners-Lee stworzył podwaliny technologii WWW. Pięć lat później założył organizację World Wide Web Consortium (W3C), ustanawiającą standardy pisania i przesyłania stron WWW. Berners-Lee do dziś jest dyrektorem W3C, którą wspierają także MIT Computer Science and Artificial Intelli-gence Laboratory (CSAIL) w USA wraz z European Research Consortium for Informatics and Mathematics (ERCIM) z siedzibą we Francji i japońskim Keio University. Działalność W3C opiera się na wpłatach od członków, funduszach na badania i innych, prywatnych i publicznych, źródłach finansowania. Warto też wiedzieć, że Berners-Lee przedstawił wizję Sieci semantycznej już w 1999 roku. (Źródło: www.w3c.org)
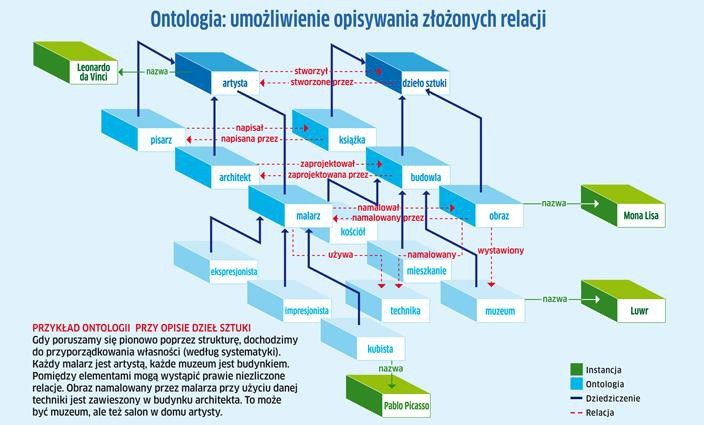
Taksonomia: struktura ściśle hierarchiczna
Reprezentacja taksonomii to próba ułożenia istniejącego zbioru elementów systematycznie i hierarchicznie. Znany przykład: taksonomia w świecie zwierząt, która przez lata drastycznie się zmieniła. U zarania, w czasach zoologa Brehma (patrz poniżej) struktura liczyła kilka poziomów i kończyła się na szympansach. Tymczasem nowoczesny system (po prawej stronie) zawiera aż 16 poziomów, w przypadku których obowiązujący kierunek to góra–dół.
Żyjący w XIX w. niemiecki zoolog Alfred Brehm stworzył podstawy taksonomii świata ożywionego. Gdy w 1869 r. wydana została książka “Życie zwierząt”, przylgnął do niego przydomek “ojciec zwierząt”.


LISTING 1
<?xml version=’1.0′ encoding=’utf-8′?>
<rdf:RDF xmlns:rdf =’http://www.w3.org/1999/02/22-rdf-syntax-ns#’
xmlns:rdfs=’http://www.w3.org/2000/01/rdf-schema#’
xmlns:ns =’http://example.org/’><rdf:Description rdf:about=’http://example.org/Prasa’>
<rdf:type rdf:resource=’http://www.w3.org/2000/01/rdf-schema#Class’/>
</rdf:Description><rdf:Description rdf:about=’http://example.org/Czasopismo’>
<rdfs:subClassOf rdfs:resource=’http://example.org/Prasa’/>
</rdf:Description><rdf:Description rdf:about=’http://example.org/Chip’>
<rdf:type rdf:resource=’http://example.org/Czasopismo’/>
</rdf:Description><rdf:Description rdf:about=’http://example.org/SemantycznaSiec’>
<ns:ArtykułW rdf:resource=’http://example.org/Chip’/>
</rdf:Description></rdf:RDF>
LISTING 2
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
_:a foaf:name “Jan Mocny” .
_:a foaf:mbox <mailto:[email protected]> .
_:b foaf:name “Piotr Dobczynski” .
_:b foaf:mbox <mailto:[email protected]> .
_:c foaf:mbox <mailto:[email protected]> .Pytanie:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT?name?mbox
WHERE
{ ?x foaf:name?name.
?x foaf:mbox?mbox }Rezultat:
name mbox
“Jan Mocny” <mailto:[email protected]>
“Piotr Dobczynski” <mailto:[email protected]>
LISTING 3
<div xmlns:dc=”http://purl.org/dc/elements/1.1/”>
<h2 property=”dc:title”>Semantyczna Siec</h2>
<h3 property=”dc:creator”>Edward Krzywy</h3><div about=”http://example.com/sw/dc.jpg”>
<img src=”http://example.com/sw/dc.jpg” />
<span property=”dc:title”>Dublin Core</span>
von <span property=”dc:creator”>Edward Krzywy</span>.
</div></div>
LISTING 4
<div typeof=”foaf:Person” xmlns:foaf=”http://xmlns.com/foaf/0.1/”>
<p property=”foaf:name”>
Alice Birpemswick
</p>
<p>
Email: <a rel=”foaf:mbox” href=”mailto:[email protected]”>[email protected]</a>
</p><p>
Phone: <a rel=”foaf:phone” href=”tel:+1-617-555-7332″>+1 617.555.7332</a>
</p>
</div>
LISTING 5
No
I used the following facts to provide this answer:
* thing that was created is the left class of ‘is older than’
* thing that was created is the right class of ‘is older than’
* the 26th of October 1947 is the birthdate of Hillary Clinton (endorse) (contradict)
* the 4th of August 1961 is the birthdate of Barack Obama (endorse) (contradict)
* ‘is older than’ is permanent (endorse) (contradict)Źródło: HTTP://BETA.TRUEKNOWLEDCE.COM/ANSWER.PHP?INPUT=IS+BARACK+OBAMA+OLDER+THAN+HILLARY-CLINTON%3F)
Linki
STANDARDY
W3C: www.w3.org
Microformats: microformats.org
Dublin Core Metadata Initiative: dublincore.ore
Friend of a Friend (FOAF) Project: www.foaf-project.orgEDYTOR OWL
Protégé: protege.stanford.edu
OBSŁUGA INTERFEJSU OWL Pellet: clarkparsia.com/pellet
KAON2: kaon2.semanticweb.orgBAZY DANYCH
Freebase: www.freebase.com
DBpedia: dbpedia.org
MusicBrainz: musicbrainz.orgSEMANTYCZNE WYSZUKIWARKI
Powerset: www.powerset.com
True Knowledge: www.trueknowledge.comANALIZA TEKSTU
Open Calais: www.opencalais.com
Gnosis: addons.mozilla.org/firefox/3999