Najnowsza aktualizacja NeMo Megatron od NVIDIA zwiększa szybkość szkolenia modeli sztucznej inteligencji o aż 30%
Zacznijmy od tego, że w 2020 roku grupa badawcza OpenAI LLC zaprezentowała światu swój model przetwarzania języka naturalnego o nazwie GPT-3. Ten może wykonywać różne zadania – od tłumaczenia tekstu po generowanie kodu oprogramowania. Z kolei zaktualizowane właśnie narzędzie NeMo Megatron zawiera teraz funkcje zoptymalizowane do szkolenia modeli GPT-3 i to nie o ledwie kilka procent, a potencjalnie aż 30%.
Czytaj też: Zewnętrzny ekran w Motoroli razr 2022 będzie bardzo użyteczny [Aktualizacja]
Trening może być teraz przeprowadzony na 175 miliardach parametrów modeli przy użyciu 1024 procesorów graficznych NVIDIA A100 w ciągu zaledwie 24 dni – skracając czas do uzyskania wyników o 10 dni lub około 250 000 godzin obliczeń na GPU, przed wprowadzeniem tych nowych wersji– czytamy na blogu firmy, opisującego tę aktualizację.
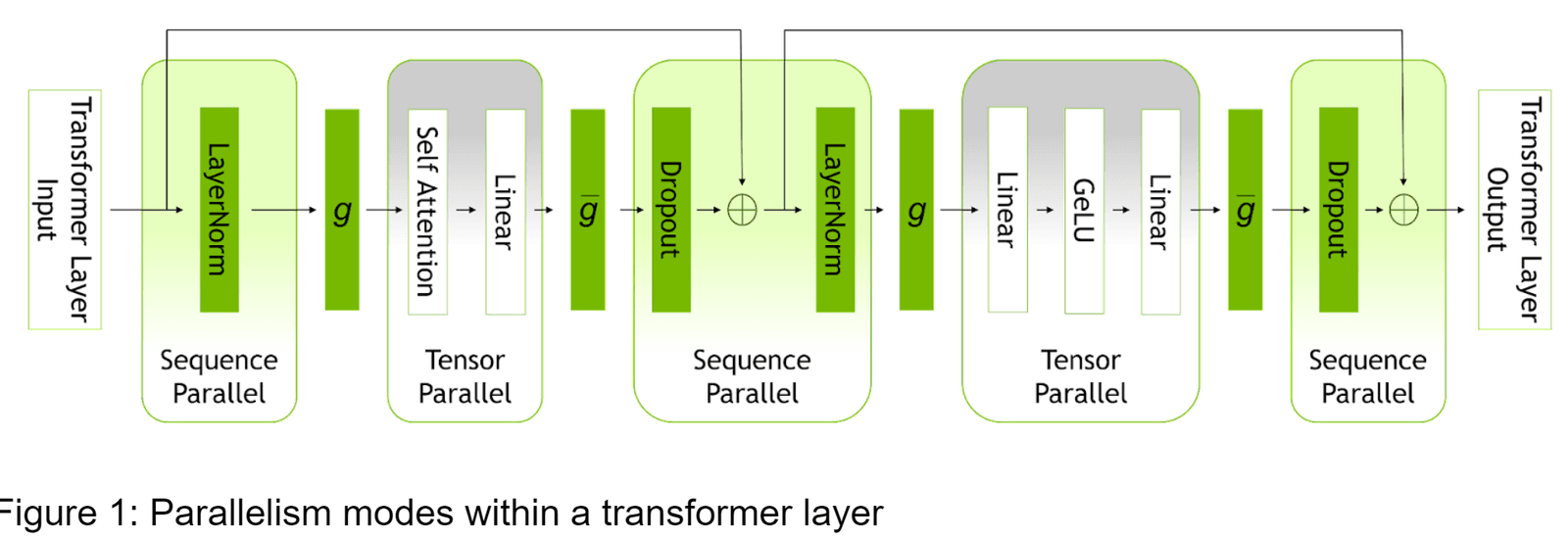
Takie wzrosty są wynikiem działania dwóch nowych funkcji znanych jako paralelizm sekwencyjny i selektywna rekomputacja aktywacji. Wedle opracowania firmy NVIDIA, każda z tych funkcji przyspiesza szkolenie SI w inny sposób i tak też w tym pierwszym przypadku model może teraz paralelizować obliczenia, które wcześniej mogły być wykonywane tylko jedno po drugim, co w ogólnym rozrachunku zwiększa wydajność. Zmniejsza też konieczność wielokrotnego wykonywania tych samych obliczeń.
Czytaj też: Jak długo będziemy jeszcze czekać na premierę Xiaomi Mix Fold 2?
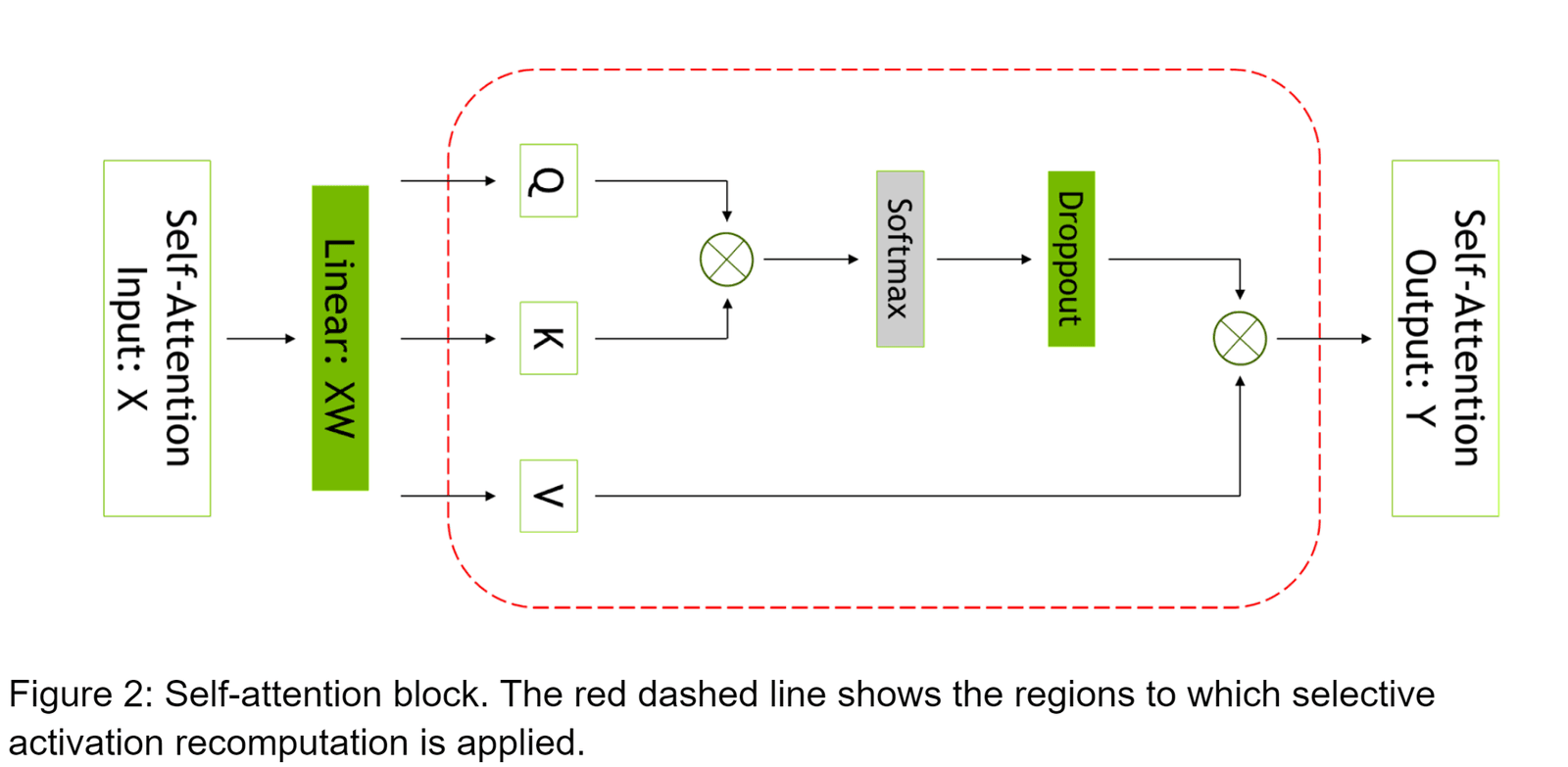
Selektywna rekomputacja aktywacji jeszcze bardziej zmniejsza liczbę obliczeń, które muszą być powtarzane. Czyni to poprzez optymalizację operacji obliczeniowych, które modele SI wykorzystują do przetwarzania danych. Jeśli obliczenia związane z aktywacją muszą być ponownie wykonane, NeMo Megatron może teraz zrobić to bardziej wydajnie i tym samym szybciej niż wcześniej.
Czytaj też: Tytanowy i elegancki. Oto Huawei Watch 3 Pro New
NVIDIA wprowadziła też narzędzia do optymalizacji hiperparametrów, czyli ustawień konfiguracyjnych, które zespoły programistów definiują dla modelu SI w trakcie jego rozwoju, aby zoptymalizować jego wydajność. Dzięki tym narzędziom zespoły programistów mogą zautomatyzować część ręcznej pracy związanej z tym zadaniem. W praktyce wygląda to tak, że twórcy mogą określić, jakie poziomy opóźnienia lub przepustowości powinien osiągnąć model SI, a nowe narzędzie automatycznie znajdzie hiperparametry niezbędne do spełnienia wymagań.