
Zespół 20 badaczy, skupionych wokół Katedry Sztucznej Inteligencji na Politechnice Wrocławskiej, przepuścił przez ChatGPT ponad 38 tysięcy zapytań z 25 zestawów danych skoncentrowanych na różnych tematach.
Naukowcy starali się znaleźć odpowiedź na kilka fundamentalnych pytań: czy na obecnym etapie chatbot OpenAI, poza oczywistym potencjałem syntezy informacji z wielu źródeł, zrozumie bardziej ludzką odsłonę komunikacji, taką jak emocje? Jak wypada w tym zadaniu na tle najlepszych, ale bardziej specjalizowanych modeli NLP, takich jak T5 czy BERT?
ChatGPT pod lupą Polaków z projektu CLARIN-PL
Badanie ChatGPT odbyło się w ramach CLARIN-PL, największego w Polsce projektu rozwoju sztucznej inteligencji, finansowanego ze środków publicznych. Za cel inicjatywy, w którą zaangażowane jest obecnie sześć instytutów oraz 20 firm, naukowcy stawiają opracowanie narzędzi do automatycznego przetwarzania danych tekstowych, głównie w naszym rodzimym języku. CLARIN-PL to polski węzeł powołanej do życia w 2012 roku Europejskiej Infrastruktury Badawczej CLARIN (Common Language Resources and Technology Infrastructure).
Wspomniane 25 zestawów danych tematycznych zawierało m.in. klasyfikację treści o charakterze agresywnym, humorystycznym czy sarkastycznym. Bardziej zaawansowane zadania dotyczyły rozpoznawania ogólnego przekazu emocjonalnego zaszytego w tekstach. Do większości zapytań naukowcy wybrali dostępne publicznie zestawy danych, skoncentrowane na konkretnym charakterze treści: m.in. agresja, poprawność gramatyczna, dowcipy, sarkazm, spam, słowo w danym kontekście, powiązanie logiczne dwóch zdań czy treści o charakterze toksycznym.
Dodali do nich jednak niepublikowane wcześniej specjalistyczne zbiory (np. ClarinEmo), których ChatGPT nie miał okazji zaindeksować. Większość treści do badania (92%) zostało napisanych po angielsku, jednak za pozostałe 8% odpowiadały treści w języku polskim (wspomniane ClarinEmo to baza ponad 1100 tekstów opiniotwórczych uzupełnionych o odręczne notatki, prezentujące osiem podstawowych emocji stojących za intencjami ich autorów).
W porównaniu do innych rozwiązań językowych ChatGPT był gorszy, ale nie beznadziejny. Okazuje się, że jest to dobre narzędzie do szybkiego znalezienia odpowiedzi, ale jeśli komuś zależy na wysokiej jakości wnioskowania, to jego wyniki mogą nie być wystarczająco dobre – ocenił wyniki jeden z autorów badania, prof. dr hab. inż. Przemysław Kazienko z Katedry Sztucznej Inteligencji na Politechnice Wrocławskiej.
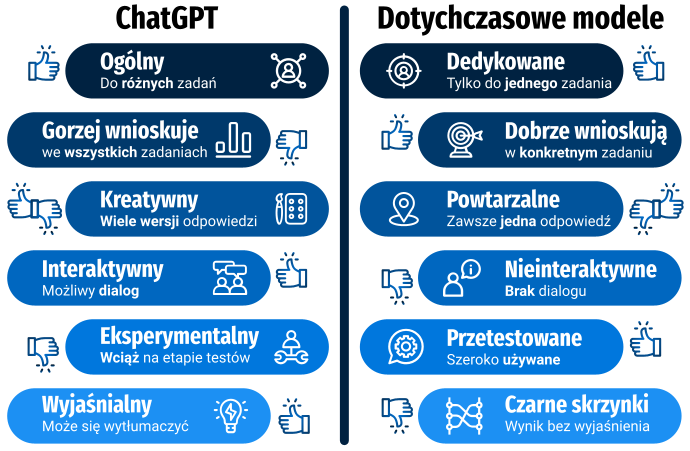
Jednocześnie zauważył, że świadomość kontekstu i możliwość personalizacji wypowiedzi okazały się mocną mocną stroną chatbota OpenAI. Z drugiej strony rozwiązanie okazało się zawodzić np. przy szybkiej zmianie tematu. Zespół planuje już dalsze badania, w których zamierza skupić się na temacie emocji, który sprawia problemy nawet wyspecjalizowanym modelom językowym.
Reasumując, im trudniejsze zadania, wymagające umiejętności właściwych dla niemal każdego dojrzałego emocjonalnie człowieka, tym gorzej radził sobie z nimi słynny ChatGPT. Skynet i Terminator jeszcze długo pozostaną czystą fantazją hollywoodzkich reżyserów, którą lubią straszyć ludzkość.
ChatGPT to ewolucja, ale nie rewolucja
W ocenie naukowców skupionych wokół projektu CLARIN-PL, chatbot od OpenAI we wszystkich z 25 przebadanych obszarów wypadł gorzej na tle swojej konkurencji. Najlepsze modele przetwarzania języka naturalnego, określane w badaniu mianem SOTA (state-of-the-art), lepiej rozpoznają emocje użytkowników, trafniej odpowiadają na pytania, a nawet notują lepsze wyniki w rozwiązywaniu zadań matematycznych.
ChatGPT podąża jednak w kierunku ogólnej sztucznej inteligencji (Artificial General Intelligence), która imituje szerokie zdolności poznawcze. Nie skupia się więc na jednej dziedzinie wiedzy, co nieuchronnie prowadzi do szeregu problemów, którym chatbot nie był w stanie stanie stawić czoła w badaniach prowadzonych na Politechnice Wrocławskiej.
Baza parametrów ChatGPT wynosi ok. 3,5 mld, ale robi duże wrażenie, jeśli chodzi o poprawność językową i brzmienie otrzymywanych treści. Choć oczywiście zdarzają mu się błędy językowe, zwłaszcza w języku polskim, który jest jednym z trudniejszych – zauważył prof. Przemysław Kazienko. Jednocześnie tłumaczy, że modele GPT indeksowały dane z wielu źródeł, wśród których warto wymienić m.in. Wikipedię, tematyczne serwisy internetowe, publiczne bazy tekstów i książek (także naukowych), a nawet blogi oraz serwisy informacyjne. To zbiór danych o pojemności przekraczającej 45 terabajtów.
Czytaj też: Wszyscy o nim mówią, mało kto go rozumie. Wyjaśniamy, co tak naprawdę potrafi ChatGPT
ChatGPT opiera swoje działanie na wielkim modelu językowym GPT-3, który został opublikowany w 2020 r., a jego pierwsza wersja powstała w roku 2018. Te daty są ważne, bo pokazują niesamowicie dużą dynamikę rozwoju tego typu modeli. Nowe rozwiązania będą się pojawiały coraz szybciej i w tym względzie uważam, że zaczęła się właśnie rewolucja sztucznej inteligencji – stwierdza prof. dr hab. inż. Przemysław Kazienko.
