
Matematyczka testuje, a Gemini znajduje subtelny błąd, który umknął ludziom
Lisa Carbone, matematyczka z Rutgers University, postawiła przed systemem niełatwe zadanie. Zamiast prostych problemów, poddała pod jego osąd zaawansowane artykuły z matematyki fizycznej. To dziedzina, w której konsekwencje nawet drobnej nieścisłości logicznej mogą być poważne. Ku jej zaskoczeniu, Deep Think wykrył subtelną wadę logiczną, która przeszła niezauważona przez ludzkich recenzentów. Ten przypadek pokazuje potencjalną rolę takich systemów – nie jako zamiennika eksperckiej wiedzy, ale jako dodatkowego filtra weryfikacyjnego. W czasach ogromnej presji na publikacje, każde narzędzie pomagające wychwycić błędy przed drukiem może mieć znaczenie.
Prawdziwym sprawdzianem dla Gemini 3 Deep Think są oczywiście praktyczne problemy laboratoryjne. Zespół Wang Lab z Duke University borykał się z wyzwaniem optymalizacji wzrostu kryształów do badań nad półprzewodnikami. Konkretnie chodziło o opracowanie metody hodowli cienkich warstw większych niż 100 mikrometrów. Dotychczasowe techniki były mało efektywne, a każda kolejna próba wiązała się z kosztami i czasem.
Według dostępnych informacji Deep Think zaproponował metodę, która w laboratorium okazała się skuteczna. System musiał wziąć pod uwagę szereg ograniczeń: właściwości materiałów, warunki procesu i możliwości dostępnego sprzętu. Podobne testy prowadził w Google Anupam Pathak, wykorzystując system do przyspieszenia projektowania fizycznych komponentów, gdzie każda iteracja oznacza realne wydatki.
Czytaj też: InPost zmienia cennik usług. Będzie taniej, acz nie dla wszystkich
Zaskakujące wyniki testów Gemini 3 Deep Think. Jak AI radzi sobie z olimpiadami
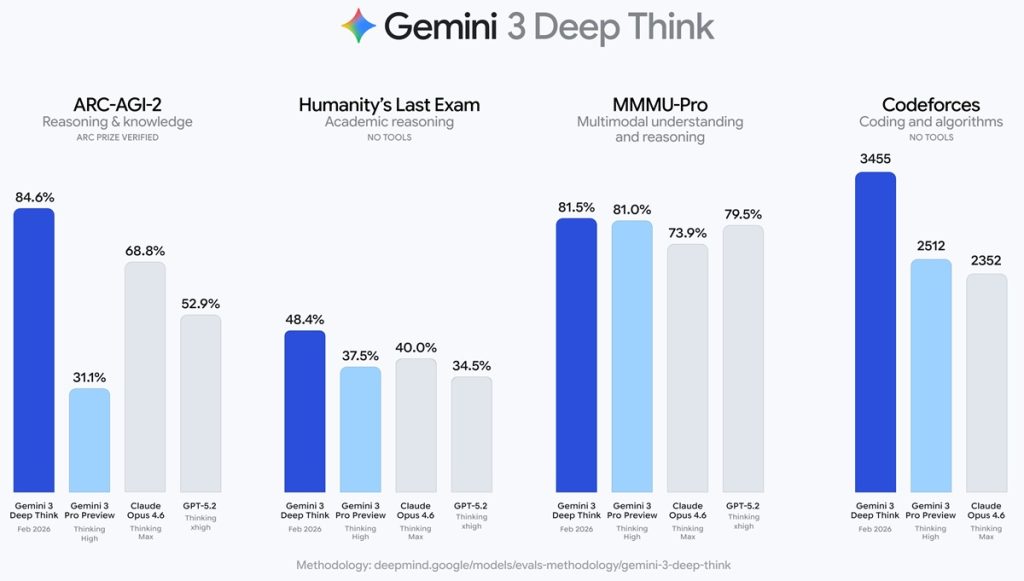
Efektywność systemu sprawdzono za pomocą standardowych benchmarków. Wyniki są interesujące, choć niejednoznaczne. Deep Think podobno osiągnął „złote” wyniki w pisemnych częściach Międzynarodowej Olimpiady Fizycznej i Chemicznej z 2025 roku. To te same arcytrudne zadania, z którymi mierzą się najzdolniejsi uczniowie na świecie.
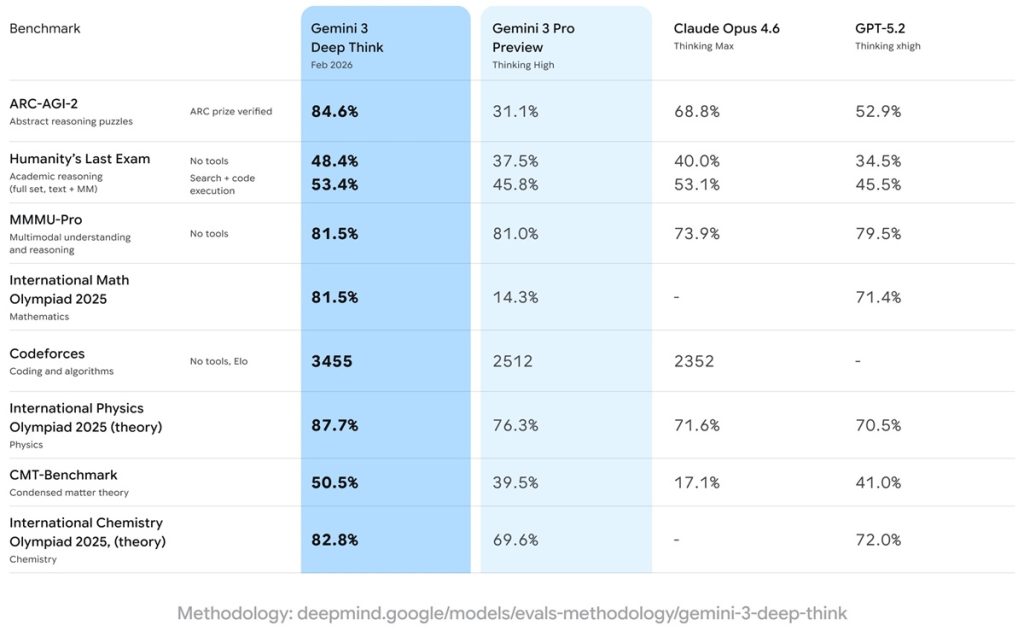
W teście CMT-Benchmark z zaawansowanej fizyki teoretycznej wynik wyniósł 50,5% – większość modeli sztucznej inteligencji nie przekracza w nim 30-procentowej skuteczności. System wydaje się szczególnie użyteczny w interpretacji złożonych zbiorów danych i modelowaniu systemów fizycznych za pomocą kodu, co wskazuje na jego przydatność w zadaniach wymagających strukturalnej analizy. Pozostaje obserwować i czekać na więcej praktycznych przykładów działania Deep Think.
