
Ponte Vecchio w skrócie, czyli GPU, jakiego jeszcze nie było
Na samym początku warto przybliżyć, czym procesory graficzne Ponte Vecchio są, bo prezentują sobą zupełnie nowe podejście do projektowania GPU. Ten jako pierwszy w historii sięgnął po łącznie 47 matryc krzemowych produkowanych w aż 5 różnych węzłach produkcyjnych, co czyni go najbardziej złożonym akceleratorem HPC na rynku. Bazuje on na architekturze Xe-HPC o konstrukcji wielomatrycowej (MCM), obejmującej układy krzemowe Compute, Rambo, HBM i EMIB o łącznej liczbie 100 miliardów tranzystorów.
Czytaj też: Szczegóły o procesorze graficznym kart Radeon RX 8000 na bazie RDNA4

Najważniejszą częścią tych procesorów graficznych są Xe-Core, czyli rdzenie obliczeniowe, zawierające po 8 silników wektorowych i matrycowych, działających na odpowiednio 512-bitowych i 4096-bitowych magistralach. Te grupy składają się na Xe Slice, będące głównym elementem składowym GPU, łączącym w sobie po 16 Xe-Core i odpowiadających im 16 rdzeni RT z myślą o śledzeniu promieni.

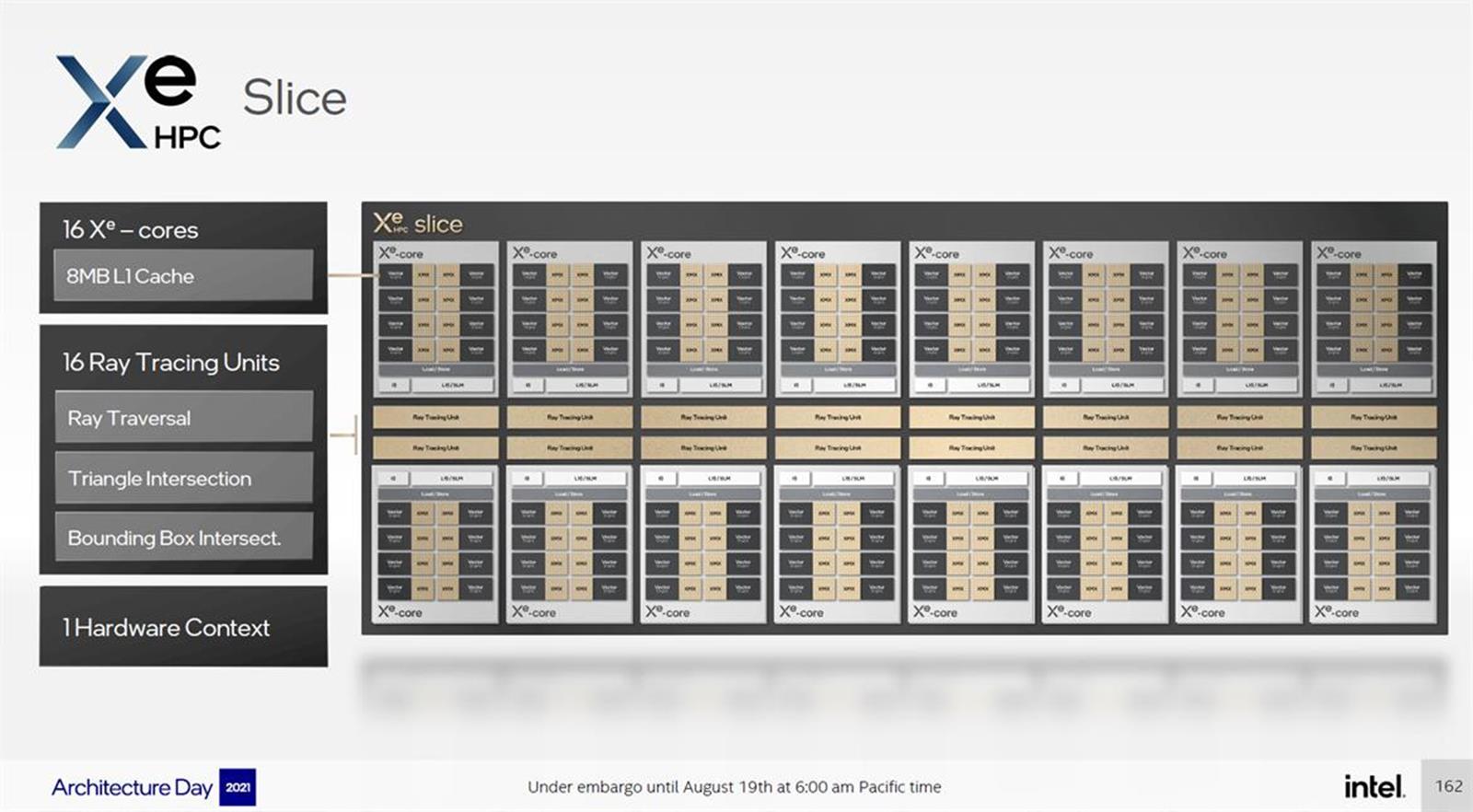
Wiemy też, że Intel Ponte Vecchio będzie dostępny w konfiguracjach z 1 i 2 stosami, dzięki czemu flagowy model będzie oferował 128 Xe-Core i 128 jednostek Ray Tracing i dostęp do 8 kontrolerów pamięci HBM2e. Ten flagowiec jest zresztą bohaterem dzisiejszego wpisu, a jego premiera będzie miała miejsce na początku następnego roku.
Jaką wydajność zaprezentował sobą testowy akcelerator graficzny Intel Ponte Vecchio?
Intel oficjalnie potwierdził, że Ponte Vecchio w wersji krzemowej A0 osiągnął już 45 TFLOPS wydajności obliczeniowej pojedynczej precyzji. “A0” oznacza te GPU, które są pierwszą wyprodukowaną partią, a więc prototypami, testowanymi wewnętrznie przez Intela oraz partnerów firmy, którzy na ich podstawie mogą zacząć tworzenie oprogramowania. Tego typu układy są też najczęściej taktowane niższym zegarem, aby zapewnić m.in. 100% stabilność.
Czytaj też: Nowy procesor Intel Core i5 z rodziny Alder Lake-S przetestowany

Autor serwisu TechPowerUp zabawił się w detektywa, wiedząc, że podane przez Intela 45 TFLOPS w obliczeniach FP32 zostały uzyskane z wykorzystaniem jednego Ponte Vecchio z dwoma stosami, czyli grubo ponad dwa razy więcej od konkurencyjnego A100 NVIDIA i prawie dwa razy więcej od MI100 od AMD. Intel w prezentacji wspomniał, że każdy pakiet zapewnia przepustowość 32768 operacji FP32 na cykl zegara, co łatwo potwierdzić, mnożąc 128 rdzeni Xe z 256 operacjami FP32 na cykl.
Czytaj też: Tak przełączają się atomy. Naukowcom udało się uwiecznić ten proces
Po podzieleniu 45000 TFLOPów przez 32768 operacji FP32 na zegar dostaniemy liczbę 1373 MHz, która odpowiada częstotliwości taktowania. To najpewniej nie jest finalne, bo choć już przy tym zegarze Intel musiał sięgnąć po chłodzenie wodne, a sam GPU pożera ponoć 600 W, to są szanse, że firma podbije taktowanie jeszcze wyżej, a wtedy wydajność urośnie liniowo.
