
Językowa potęga na wyciągnięcie ręki. Oto model MT-NLG na bazie sztucznej inteligencji
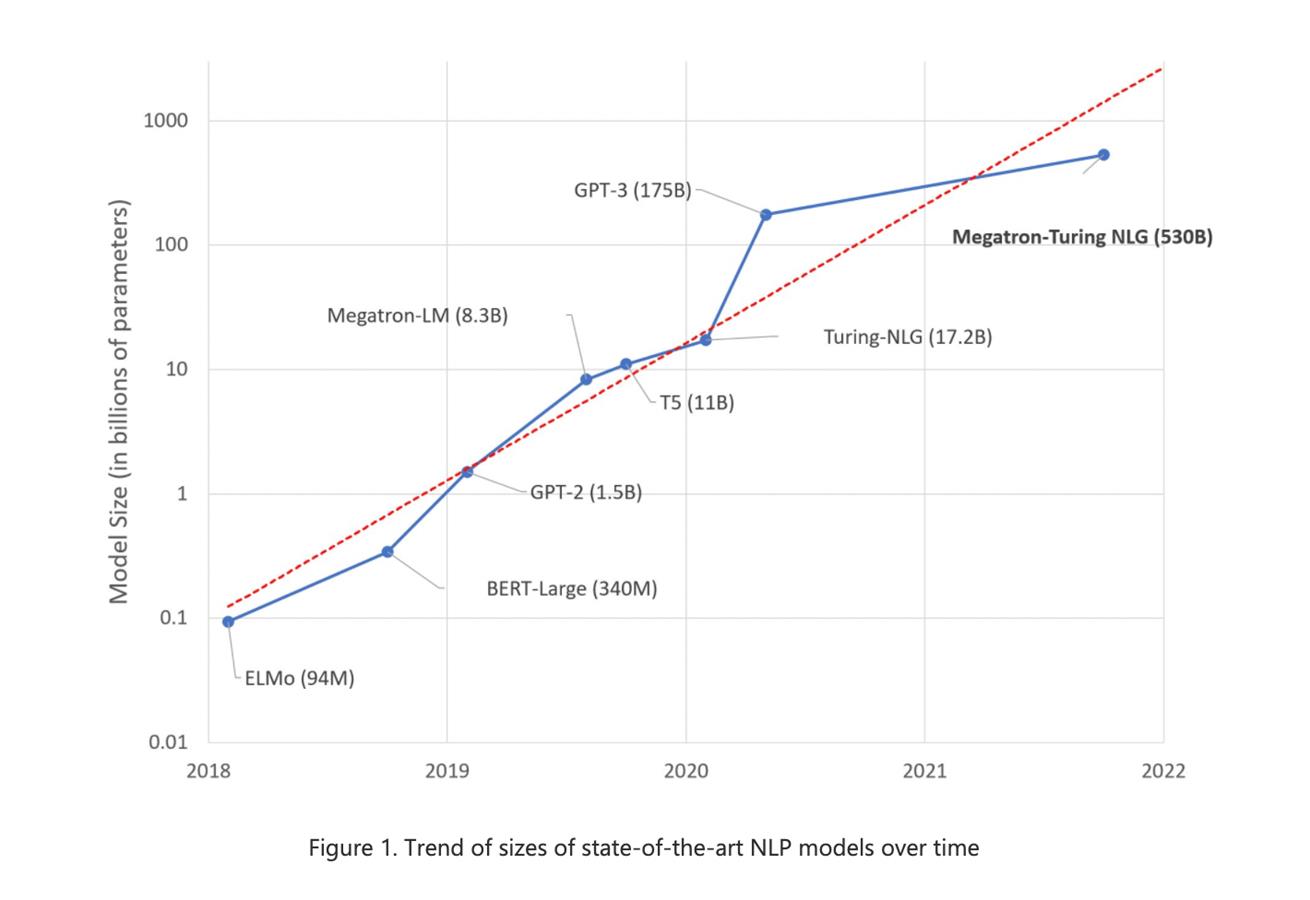
Zacznijmy może od podkreślenia potęgi modelu MT-NLG, co jest skrótem od Megatron-Turing Natural Language Generation Model. Ten może pochwalić się treningiem obejmującym 530 miliardów parametrów, podczas gdy przykładowo GPT-3 OpenAI bazuje na 175 miliardach parametrów, a wspomniane wyżej autorskie dzieła Microsoftu i NVIDIA na około trzy razy mniejszej ich liczbie. Jeśli o te modele na bazie sieci neuronowych idzie, im jest tych parametrów więcej, tym lepiej.
Czytaj też: Sztuczna inteligencja Chin nie do doścignięcia, czyli jak przegraliśmy wojnę SI
Dlatego też model MT-NLG świetnie radzi sobie z operowaniem na języku i wykonywaniu związanych z nim poleceń, pokroju automatycznego uzupełniania zdań, zadawania pytań i odpowiadania na nie, jak również czytania czy wnioskowania. Może również wykonywać te zadania z niewielkim, a nawet zerowym dostrajaniem, podczas gdy zaplecze technologiczne, które posłużyło do przekucia planów na rzeczywistość, przytłacza ceną szacowaną na ponad 85 miliona dolarów.
Szkoleniem MT-NLG zajął się bowiem superkomputer NVIDIA Selene, a więc system, bazujący na 560 serwerach DGX A100, z czego każdy jeden składa się z aż ośmiu akceleratorów graficznych A100 z 80 GB pamięci VRAM. Wszystkie 4480 akceleratory są połączone ze sobą poprzez NVLink oraz NVSwitch, a uzupełniają je procesory AMD EPYC 7v742.
Czytaj też: Sztuczna inteligencja będzie w stanie wyobrazić sobie rzeczy, których nigdy nie widziała
Jednak nawet tak solidne zaplecze technologiczne nie wystarczyło, aby szkolenie MT-NGL poszło z płatka i dlatego wykorzystano w tym celu bibliotekę DeepSpeed. Ta pozwoliła inżynierom na zagęszczenie danych równolegle w wielu potokach, aby przyspieszyć szkolenie na bazie 1,5 TB danych, obejmujących angielskie teksty, co finalnie trwało nieco ponad miesiąc. Nic dziwnego.
Czytaj też: Po raz pierwszy sztuczna inteligencja wykryła cel do zlikwidowania
MT-NLG został przeszkolony na gigantycznym zbiorze danych “The Pile” z 825 GB tekstu, który stworzyła grupa badaczy i inżynierów, działających wspólnie pod nazwą Eleuther AI. Ci, od dłuższego czasu, oddolnie prowadzą prace nad modelami dużych języków typu open source i niestety, zgromadzony przez nich tekst (270 miliardów rekordów) nie został stosownie przefiltrowany, co oznacza, że MT-NLG może generować obraźliwe treści, które mogą być rasistowskie lub seksistowskie. To problem, który NVIDIA i Microsoft mają zamiar rozwiązać.
