
Chociaż omawiamy tutaj temat układu przeznaczonego dla profesjonalistów i przedsiębiorstw, musicie wiedzieć, że na konsumenckim rynku tego typu procesory również się pojawią. Pierwszym z nich będzie Ryzen 7 5800X3D, w którym zastosuje się właśnie technologię pakowania 3D, dodając za jej pomocą dodatkowy pokład pamięci cache poprzez dołączenie jej “od góry” układów krzemowych. Samo określenie “wafer-on-wafer” wskazuje na to bezpośrednio, bo oznacza “układ na układzie”.
Czytaj też: Jeszcze szybsza pamięć operacyjna dla smartfonów. Qualcomm zweryfikował LPDDR5X
Technologia produkcji TSMC 3D poprawiła wydajność procesorów SI, dopinając do nich… układ odpowiadający za dostarczanie energii
Firma Graphcore pochwaliła się nowym układem Bow, który powstał poprzez połączenie drugiej generacji procesorów sztucznej inteligencji (SI) z krzemową matrycą odpowiadającą za dostęp do energii. Ta została dołączona do tych pierwszych (tak zwanych IPU – Intelligence Processing Units w liczbie 1472 sztuk z dostępem do 900 MB pamięci) w procesie SoIC WoW firmy TSMC.
Czytaj też: Pierwszy procesor Alder Lake-S dla laptopów, czyli Intel Core i7-12650HX
Oznacza to, że połączono dwa całe matryce krzemowe z miedzianymi podkładkami i wypustkami, które idealnie do siebie pasują. Dzięki temu, gdy oba układy zostają do siebie dociśnięte w procesie produkcyjnym, wypustki łączą się ze sobą. Podczas gdy jeden układ odpowiada za sferę obliczeniową, ten drugi umieszczony bezpośrednio na nim, ma za zadanie wyłącznie dostarczać energię. Dlatego też składa się głównie z kondensatorów i przelotek (pionowych połączeń), które tworzą połączenia zasilania i danych.
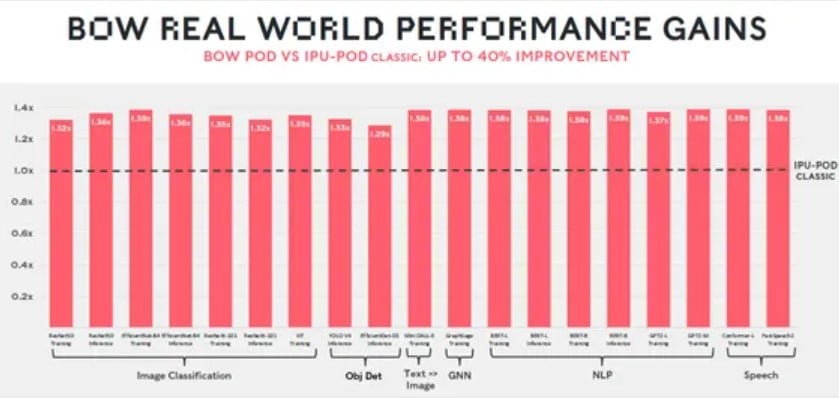
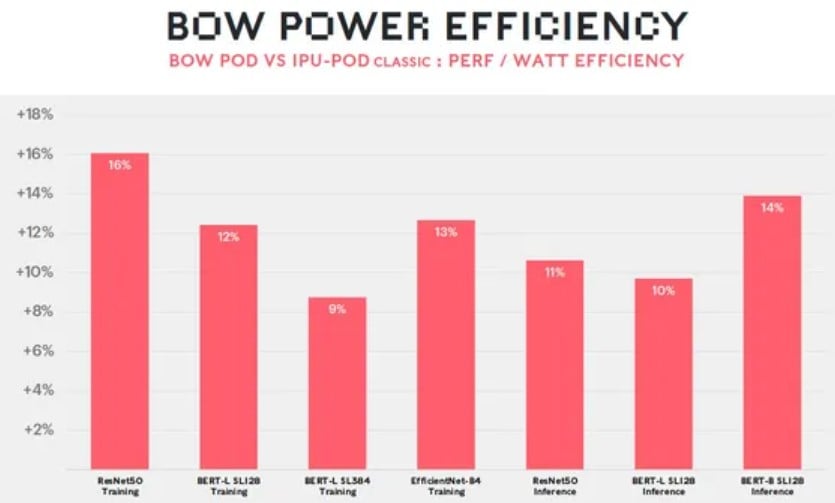
Finalnym efektem jest układ Bow, który może pracować na taktowaniu rzędu 1,85 gigaherca, a nie 1,35 GHz (jak wersja bez układu zasilającego w pakiecie 3D) i jednocześnie na niższym napięciu. To z kolei przełożyło się na wzrosty wydajności komputerów trenujących sieci neuronowe o 40% i obniżenie poboru mocy o 16%, a to wszystko przez najważniejszą zaletę technologii “krzem na krzemie”.
Czytaj też: Intel może zmusić nas do DDR5. Oto wszystko co musicie wiedzieć o Raptor Lake [Aktualizacja]
Ta pozwala uzyskać okazalszą gęstość połączeń między układami niż w przypadku mocowania pojedynczych układów do krzemu. W tym konkretnym przypadku mowa dokładnie o kondensatorach, które są formowane w tym dodatkowym rdzeniu w postaci głębokich, wąskich rowków w krzemie i znajdują się bardzo blisko tranzystorów. Dzięki temu lepiej realizują proces dostarczania energii, a to pozwala na szybszą pracę rdzeni IPU przy niższym napięciu.