
NVIDIA CPU Grace Supership
Jako że zapewne jesteście tutaj głównie dla architektury Hopper i rdzeni graficznych GH100, zaczniemy od CPU Grace, żeby skorzystać z Waszej uwagi i chęci do poznawania nietypowych nowości w ofercie NVIDIA. Firmę kojarzymy bowiem głównie z kart graficznych, a nie procesorów z oczywistych względów, dlatego wiadomości o Grace określanym mianem CPU Superchip mogą nie spotkać się z szerszym komentarzem.
Czytaj też: Ropa solą naszych czasów, czyli o sprzeciwie względem elektrycznych samochodów i ropnej potędze

W praktyce te “superukłady procesorowe”, to sprzęt przeznaczony do zastosowań HPC (High-Performance Computing) oraz obliczeń związanych ze sztuczną inteligencją. Przyjmuje postać pakietu z dwoma procesorami Grace o 72 rdzeniach opartych o architekturę Arm v9 każdy. Te mają dostęp do nieznanej na ten moment pamięci LPDDR5X z korekcją błędów poprzez interfejs o przepustowości 1 TB/s, jak również koherentne połączenie pamięci podręcznej NVLink-C2C, które zapewnia przepustowość rzędu 900 GB/s, czyli siedem razy większą niż protokół PCIe 5.0.

Jako że dostawy Grace CPU Superchip będą realizowane dopiero w pierwszej połowie 2023 roku, to na ten moment mamy dostęp tylko do symulowanej wydajności, o której lepiej nie pisać. Na szczegóły będziemy więc musieli poczekać, ale potencjalnie ten procesor może sprawić, że razem z akceleratorami graficznymi NVIDIA będzie mogła projektować superkomputery i kompleksowe centra danych wyłącznie na bazie własnego sprzętu obliczeniowego.
NVIDIA GH100 Hopper, czyli procesor graficzny z 80 miliardami tranzystorów
W 2016 roku zadebiutował układ Tesla P100 z GPU GP100, dzierżący ogromną jak na tamte czasy liczbę 15,3 miliarda tranzystorów w procesorze graficznym o wielkości 610 mm kwadratowych. W 2020 roku premierę zaliczył GA100 o wielkości 828 mm2, który miał już w sobie niebywałe 54,2 miliarda tranzystorów, a w marcu 2022 roku doczekaliśmy się nie dość, że mniejszego (mierzącego 814 mm2), to na dodatek bogatszego w tranzystory (ma ich aż 80 miliardów) rdzenia GH100, który stanowi podstawę akceleratorów H100.
Czytaj też: Jak wykorzystać sieć 5G? Wiele gałęzi przemysłu już wie jak to zrobić
Procesor GH100 jest produkowany z wykorzystaniem procesu produkcyjnego TSMC N4, a nie N7, jak GA100, co jednoznacznie wyjaśnia powód różnicy w liczbie tranzystorów. W pełnej implementacji GH100 ma do zaoferowania 144 klastrów (SM), co przekłada się na 18432 rdzeni CUDA (FP32), a to oznacza, że każdy klaster zapewnia 128 rdzeni FP32.
Dodatkowo posiada 60 MB pamięci podręcznej poziomu drugiego, 576 rdzeni Tensor nowej, bo 4. generacji oraz możliwość skonfigurowania z 6 stosami pamięci HBM3/HBM2e za pośrednictwem dwunastu 512-bitowych kontrolerów. Unikalność zapewnia mu też wsparcie technologii NVLink 4. generacji oraz standardu PCIe 5.0, co jest gwarantowane niezależnie od wersji, bo musicie wiedzieć, że GH100 trafia w dwóch różnych konfiguracjach do wariantu opartego o interfejs SXM5 i PCIe 5.0.
Te dwa akceleratory cechuje TDP na poziomie kolejno (SXM5 vs PCIe 5.0) 700/350 watów, dostęp do 132/114 klastrów graficznych, czyli 16896 lub 14592 rdzeni CUDA. GPU z dostępem do 50 MB pamięci podręcznej jest połączone z pamięcią w ramach 5 stosów za pośrednictwem 5120-bitowej magistrali, która w wersji SXM5 sięga 80 GB HBM3, a w wersji PCIe 5.0 tę samą pojemność standardu HBM2e. Różnica przepustowości wynosi 1 TB/s (3 vs 2 TB/s).
Czytaj też: Maszyna wirtualna w Hyper-V. Podpowiadamy, jak zainstalować system w systemie
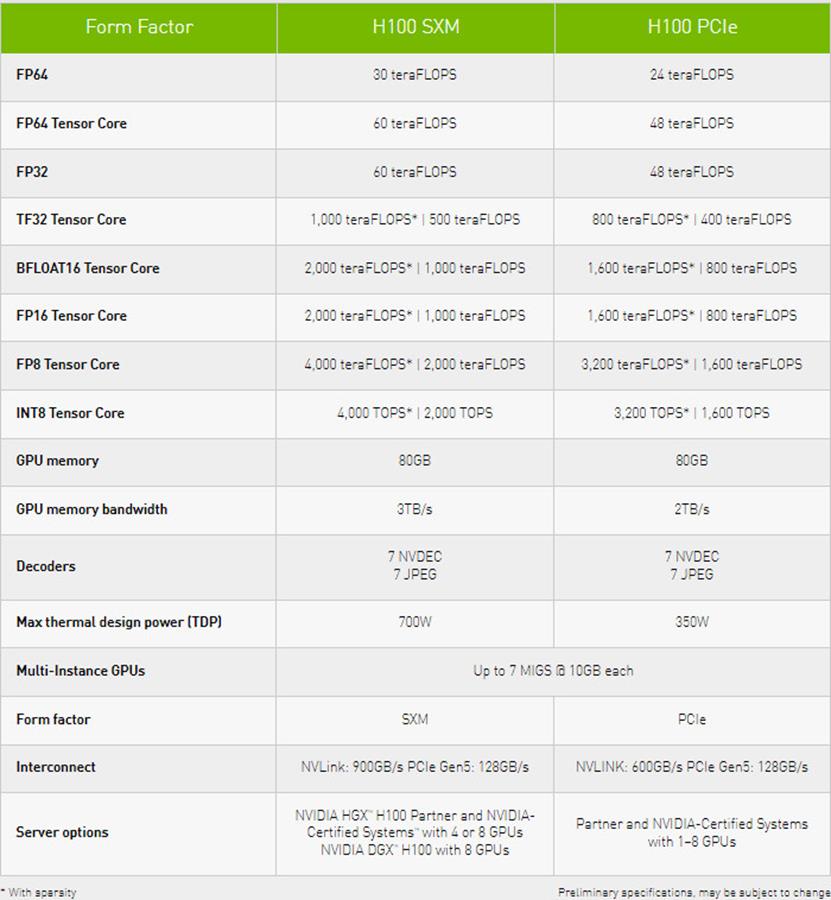
Powyżej możecie rzucić okiem, co to oznacza po stronie wydajności, która oczywiście jest ogromna. Zwłaszcza w praktycznym użyciu, bo w serwerach można łączyć te akceleratory w zestawy nawet ośmiu egzemplarzy. Nie będę jednak rozpisywał się na temat wydajności, którą trudno odnieść do rzeczywistych możliwości i zamiast tego skupię się na szczegółach architektury i nowych instrukcjach, które GH100 obsługuje.
Tymi instrukcjami są tak zwane DPX, mające na celu przyspieszyć programowanie dynamiczne. Są wykorzystywane w szeregu algorytmów, w których spisują się lepiej o 40 razy względem wydajności oferowanej przez procesory centralne i siedmiokrotnie w porównaniu z procesorami graficznymi poprzedniej generacji. Tyczy się to m.in. algorytmu Floyda-Warshalla i Smitha-Watermana, czyli podstaw do zapewniania autonomiczności robotom w magazynach czy zabawie z białkami oraz DNA.

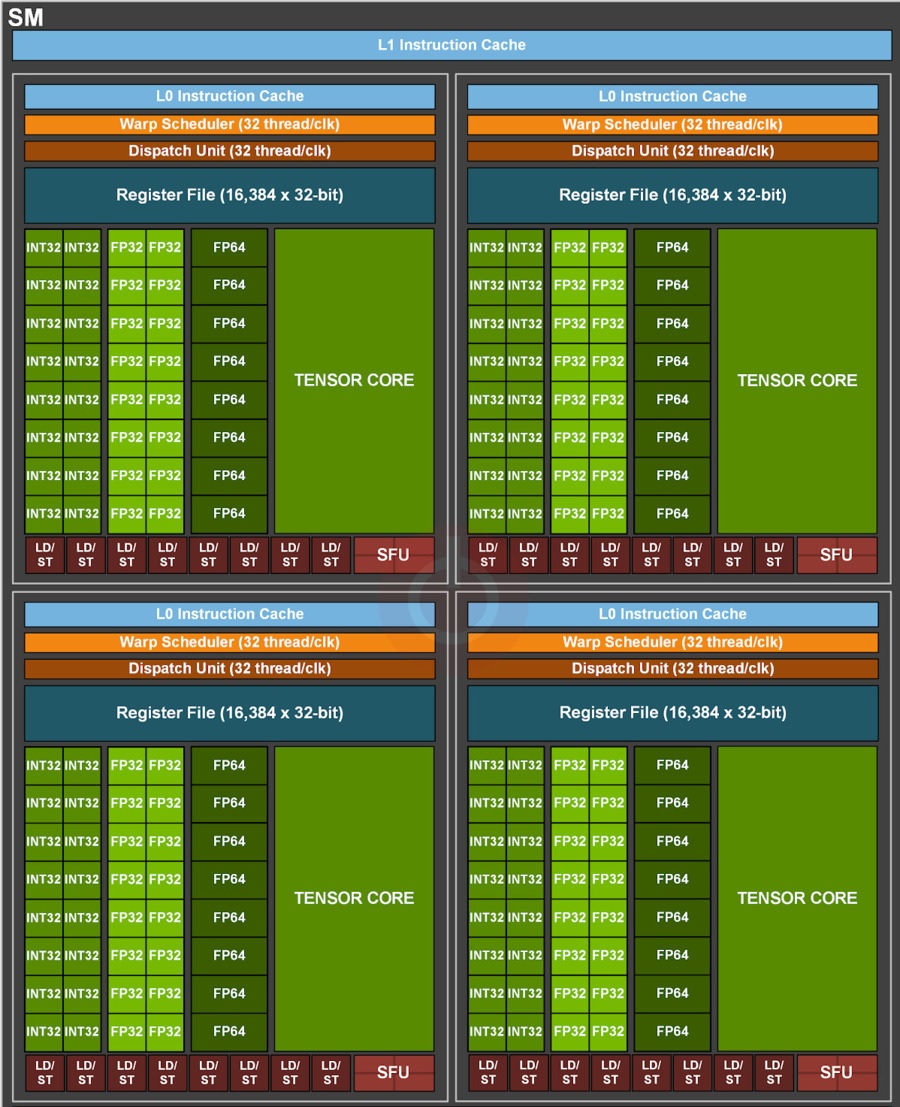
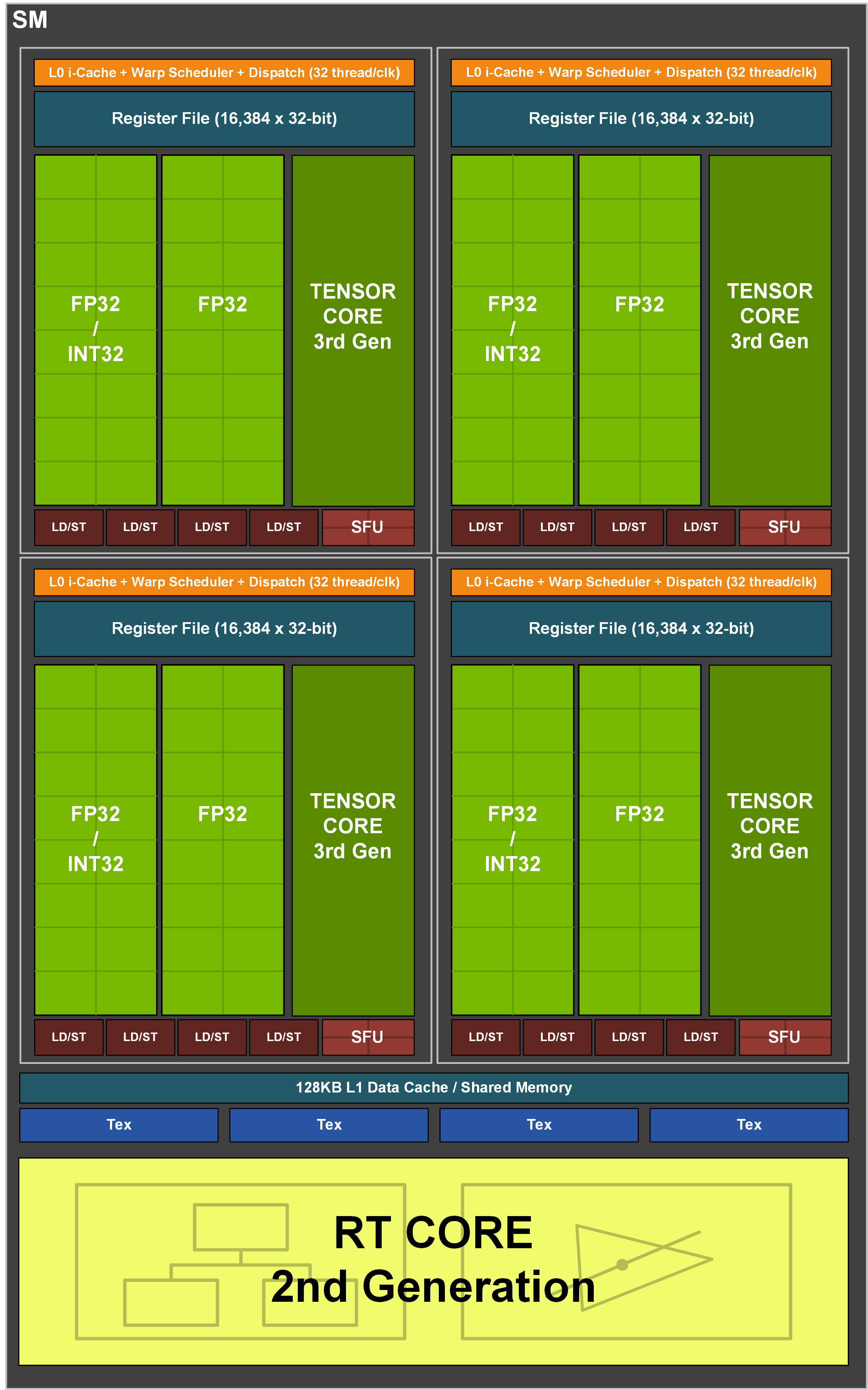
Powyżej możecie z kolei obejrzeć to, co buduje każdy z klastrów (jednostek SM) procesorów graficznych GH100, GA100 oraz GA102 (kolejno). Porównujemy więc tutaj procesor profesjonalny nowej generacji, starszej i układ do zastosowań konsumenckich. Nietrudno zauważyć, że różnice między nimi są ogromne i nie chodzi tutaj o generacje rdzeni Tensor, a rodzaj i liczbę jednostek.
W GH100 liczba jednostek obliczeniowych FP64 wzrosła dwukrotnie (16 vs 8), co tyczy się też FP32 (16 vs 32), ale nie jednostek obliczających liczby całkowite (INT32). Te pozostały bez zmian i nadal sięgają 16 jednostek. Wspominam o tym nie bez powodu, bo jak widzicie na diagramie GA102, w nim NVIDIA połączyła połowę jednostek FP32 z INT32, zapewniając tak zwane “fałszywe rdzenie”, które dla wielu bardziej obeznanych nieco mącą w specyfikacji.
Dlaczego? Bo gdy dana jednostka zajmuje się obliczeniami INT32, jednocześnie nie może wykonywać FP32. Wnioski pozostawiam Wam i warto o nich pomyśleć zważywszy na nadchodzącą premierę RTX 4000 z nowymi GPU na bazie architektury Ada Lovelace.
