
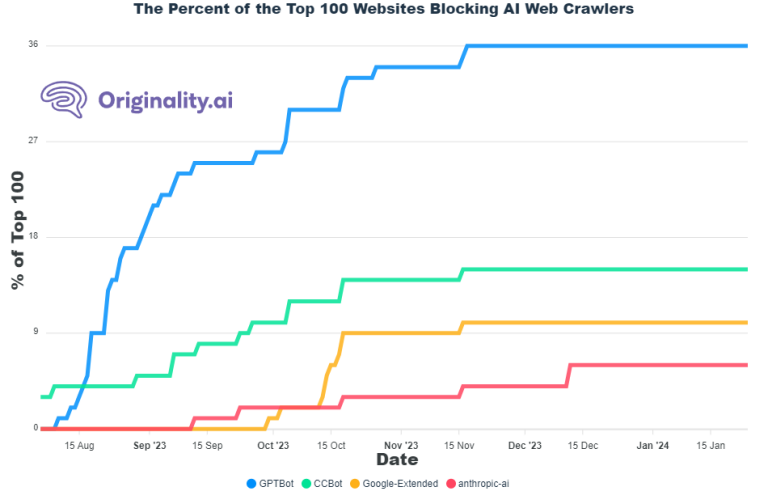
BBC, Bloomberg, Forbes, The New York Times, Reuters,The Wall Street Journal, The Verge – to tylko najbardziej rozpoznawalne serwisy informacyjne, które nie chcą, aby ChatGPT grzebało im w treściach. Ogólnie niechęć do SI żywi ponad 1/3 ze stu najpopularniejszych stron na świecie. Ale zauważmy, że zakaz dostał nie tylko model OpenAI, ale również podobne rozwiązania od Google’a i innych producentów.
ChatGPT a prawa autorskie
Powodem, dla którego wyżej wymienione witryny blokują roboty ChatGPT, jest łamanie praw autorskich. Tu muszę przypomnieć, że szkolenie sztucznej inteligencji odbywa się za pomocą tysięcy tekstów, z których uczy się ona zwrotów, zdań, opisów, wyrażeń itp. A skąd te teksty? Oczywiście z witryn internetowych, a także baz danych gromadzących pliki PDF i inne treści. Problem z witrynami jest jednak taki, że zarówno treści ogólnodostępne, jak i te płatne – czyli wyłącznie dla abonentów – są chronione prawami autorskimi. A jakby nie było ich wykorzystywanie w celu szkolenia SI, które później przyniesie zresztą dochód – podpada pod określenie “nielegalne wykorzystanie”.
Ale ban nie dotyczy tylko serwisów informacyjnych – podobne rozwiązania blokujące dostęp SI do treści wprowadziły Amazon, Facebook, Shutterstock czy Rotten Tomatoes. Oznacza to, że modele językowe mają dostęp do mniejszych ilości treści, co może spowodować spowolnienie ich rozwoju. A w jaki sposób są blokowane? Po prostu w kodzie witryny umieszcza się mechanizmy, które blokują roboty skanujące treści.
Czytaj też: Wojsko czeka rewolucja. W USA zakończono testy sprzętu przyszłości
Aby zablokować boty wysłane przez SI, wystarczy wprowadzić do kodu strony zaledwie parę linijek z odpowiednią komendą, np. GPTBot Disallow: / czy Google-Extended Disallow: /. Irytację twórców treści oraz samych autorów powoduje także fakt, że nie można sprawdzić, czy dane treści są wykorzystywane do szkolenia SI. Zdarzało się jednak, że ChatGPT w odpowiedzi na zapytania pisał teksty, w których treści były żywcem skopiowane z konkretnych witryn.
Regulacje dotyczące praw autorskich nie przewidziały wykorzystywania tekstów w takich celach. Prawo musi więc nadgonić rzeczywistość, a wówczas ChatGPT będzie mógł działać legalnie. Warto jednak zauważyć, że wiele serwisów nie ma nic przeciwko użyczaniu swoich treści sztucznej inteligencji – tu mogą wymienić Wikipedię, YouTube, X i wiele innych. A więc podejście do problemu może być różne.
