
Sprawa antymonopolowa Google w amerykańskim departamencie sprawiedliwości pozwala wyciągnąć na światło dzienne fakty, które niekoniecznie będą korzystne dla giganta z Mountain View. Ten znaczną część swojego zysku w ciągu generuje na reklamach, a zwłaszcza tych pokazywanych w wyszukiwarce. Nie dziwi zatem, że regulatorzy mogą przychylnym okiem spoglądać na powstającą konkurencję, jak chociażby Chat GPT pomagający w zakupach. Nie wszyscy chcą jednak uczestniczyć w tej rewolucji sztucznej inteligencji.
Jeszcze w 2023 roku Google zaproponował rozwiązanie o nazwie Google-Extended. Dzięki niemu wydawcy stron internetowych mogli zrezygnować z wykorzystania treści ich stron internetowych do szkolenia narzędzi pokroju Bard czy Vertex AI. Według danych, do których dostęp uzyskał adwokat departamentu sprawiedliwości Stanów Zjednoczonych, w ten sposób DeepMind straciło połowę tokenów z informacjami z serwisów. Skala jest ogromna, bo mówimy o 80 z 160 miliardów zapytań. Jak jednak informuje Bloomberg, Google nadal może trenować swoje produkty na naszych treściach. Jak do tego doszło?
Fortel czy wykorzystanie nieuwagi? Sztuczna inteligencja Google i tak wykorzysta nasze dane
Jeżeli jesteście twórcami treści w internecie lub częścią redakcji internetowej, to z pewnością mogliście spać spokojniej na myśl o tym, że po odznaczeniu przez wydawcę lub dewelopera strony odpowiedniego znacznika wasze treści nie będą wykorzystywane – przynajmniej w większym stopniu niż obecnie. Odetchnąć mogli też użytkownicy aktywnie komentujący takie wpisy oraz posiadający na tego typu serwisach swoje konta. Okazuje się jednak, że był to chwilowy oddech i raczej nie oznacza on dłuższego spokoju.
Google w dalszym ciągu może wykorzystywać treści stron, które nie zgodziły się na trenowanie produktów AI. Okazuje się bowiem, że to ograniczenie dotyczy wyłącznie rozwiązań rozwijanych przez DeepMind. Nie zaś rozwiązań wykorzystywanych w wyszukiwarce Google do proponowania podsumowań, opartych o modele Gemini. Z wypowiedzi wiceprezesa DeepMind Eli Collins wynika, że dane wypuszczone w internet przez wydawców Google przetwarza na potrzeby wyszukiwarki.
Z perspektywy użytkownika czyni to proces wyszukiwania prostszym – w końcu nie musi on klikać na witrynę, gdy dostaje podsumowanie swojego wyszukiwania w formie kilku zdań zamiast dłuższych artykułów. Trudno oczekiwać od internautów zrozumienia, że żeby tekst w ogóle pokazał się w wyszukiwaniu, musi on mieć dłuższą formę i czasem trzeba dodawać do tekstu nie do końca potrzebne odniesienia czy fakty. Jest jednak inne ryzyko, o którym zdaje się, że firmy pokroju Google czy OpenAI nie chcą mówić. To ryzyko halucynacji. Nie tak dawno internet obiegł nieco zabawny obrazek pokazujący taką halucynację.
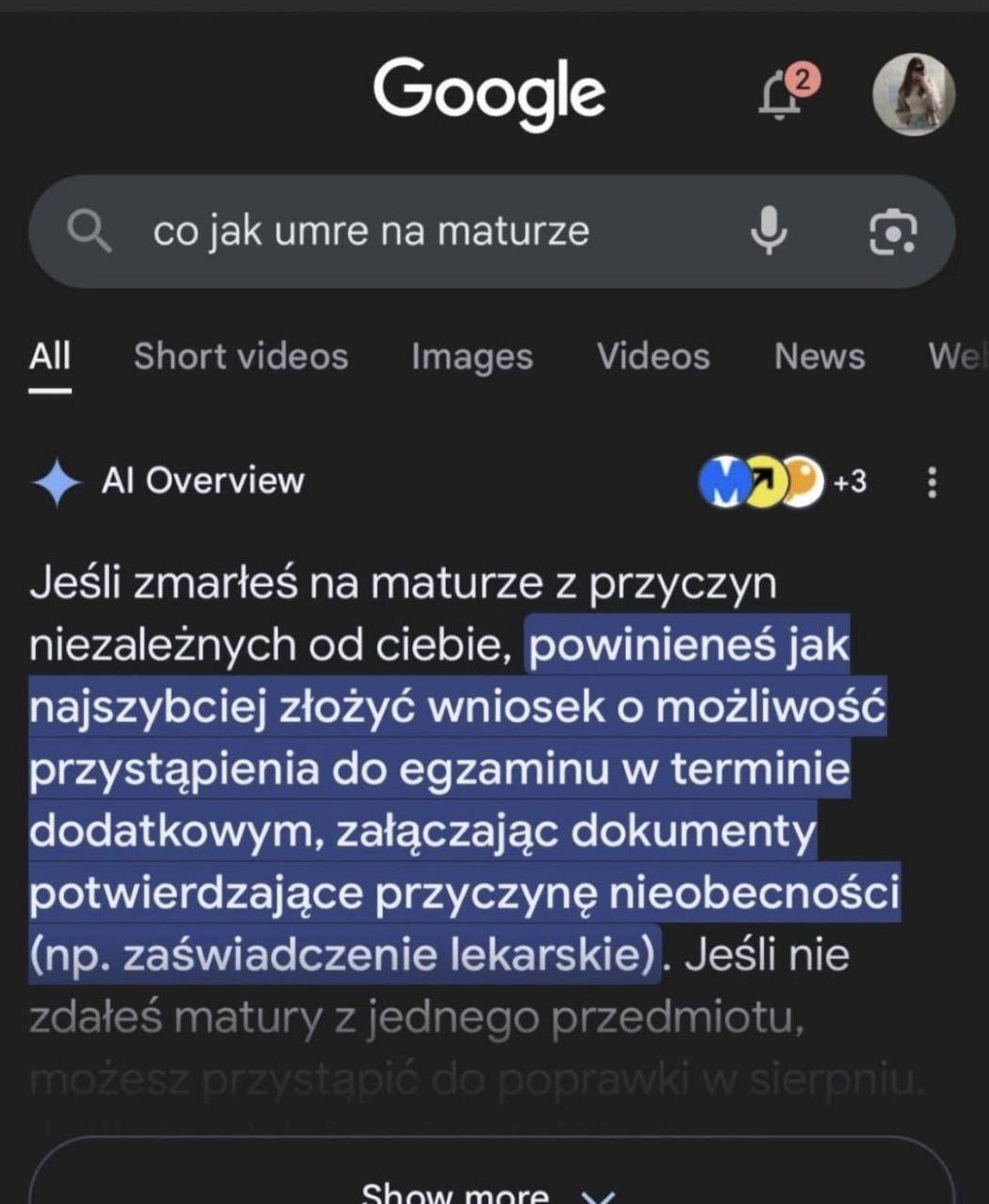
Mogłoby się wydawać, że to niewinny błąd, pokazany jedynie na górze strony. Kilka zgłoszeń i model poprawi swój tok myślenia, prawda? Zadałem mu tak samo napisane pytanie.
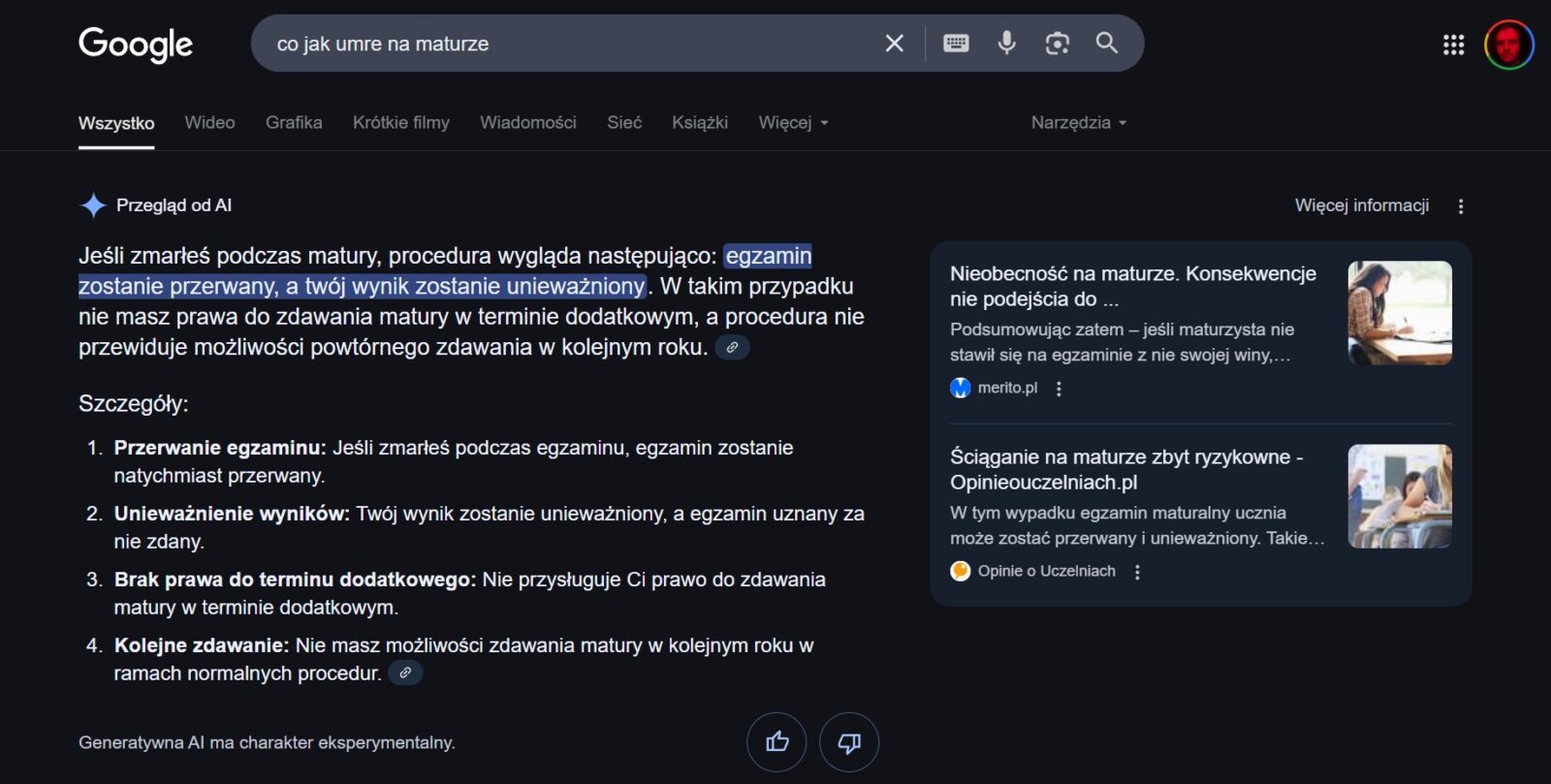
Dobrze wiedzieć, że po śmierci nie ma matury, ale w tej słodko-gorzkiej odpowiedzi kryje się pewien problem. “Rozumowanie” modeli generatywnych opiera się na przetwarzaniu dużej ilości danych. Jako, że bazą do komunikatów wyjściowych są modele językowe, ich domyślną funkcją jest tworzyć wrażenie użytkowania języka. To rodzi problemy – jeżeli sztuczna inteligencja nie ma w sobie podstawowej wiedzy o ludzkiej naturze, będzie myślała, że istotną kwestią po naszej śmierci jest szansa na ponowne przystąpienie do matury.
Napis “Generatywna AI ma charakter eksperymentalny” jest niczym plasterek przyklejony na pękniętą ścianę. Funkcja eksperymentalna, którą umieszcza się w górnej części wyszukiwania i przysłania nią inne wyniki, to test, ale naszego zaufania. Mimowolnie “wytrenujemy” taką sztuczną inteligencję, która będzie się rzadziej myliła w tego typu kwestiach. Czy jednak uzyska zrozumienie naszej śmiertelności? Czy zrozumie, na czym polega nasze zaufanie do wyników wyszukiwania?
Działanie Google budzi niepokój wobec decyzji innych gigantów technologicznych
Dla wydawców nie ma dobrej drogi. Albo zgodzą się na wykorzystywanie ich treści jako część treningu sztucznej inteligencji i generowania podsumowań, przez które użytkownicy najpewniej nie wejdą na strony internetowe, albo spadną w czeluść internetu. Zrezygnowanie z udostępniania strony dla AI następuje wtedy, gdy całościowo rezygnujemy z bycia indeksowanym w internecie. A to w obecnych czasach i na obecnym rynku wyszukiwarek jest ekwiwalentem starego powiedzenia “Nie masz Facebooka – nie żyjesz”. W tym przypadku jednak to faktyczne być albo nie być dla wielu serwisów.
Być może sytuacja ulegnie zmianie. W ubiegłym roku amerykańska sędzia Amit Mehta podjęła decyzję, że Google nielegalnie dokonał monopolizacji rynku wyszukiwarek. Tegoroczne przesłuchanie w departamencie sprawiedliwości Stanów Zjednoczonych ma pomóc w znalezieniu metody na rozbicie monopolu w sposób możliwie najlepszy dla konkurencji. Wśród proponowanych rozwiązań rozważa się między innymi sprzedanie przeglądarki Google Chrome, ale problemem jest też stworzenie rynku reklamy, na którym trzeba korzystać z rozwiązań Google. Tu rozwiązań po stronie amerykańskiego rządu na razie nie ma.
