
NVIDIA ulepszyła akcelerator Hopper H100
Architektura NVIDIA Hopper pojawiała się w przeciekach od ponad dwóch lat, a premiery doczekała się w pierwszym kwartale bieżącego roku. Wtedy dowiedzieliśmy się, że napędzi akcelerator Hopper H100, którego procesor graficzny będzie wyjątkowy, bo sprowadzi się do układu wielokrzemowego wykonanego w ramach procesu TSMC 4N. Takie podejście MCM (Multi-Chip-Module) stosowane zarówno w przypadku CPU, jak i GPU, sprowadza się do umieszczenia na jednym układzie kilku połączonych ze sobą wzajemnie krzemowych matryc, które współpracują ze sobą w czasie rzeczywistym. W dniu premiery okazało się jednak, że NVIDIA nadal będzie wykorzystywać pojedynczy, monolityczny krzem w swoim GPU.
Czytaj też: Planujesz zakup zegarka Samsung z serii Galaxy Watch5? Możesz liczyć na cashback
GPU GH100 mierzy 814 mm2 i ma aż 80 miliardów tranzystorów. Dla przypomnienia, w 2016 roku zadebiutował układ Tesla P100 z GPU GP100, dzierżący ogromną jak na tamte czasy liczbę 15,3 miliarda tranzystorów w procesorze graficznym o wielkości 610 mm kwadratowych. W 2020 roku premierę zaliczył GA100 o wielkości 828 mm2, który miał już w sobie niebywałe, jak na tamte czasy 54,2 miliarda tranzystorów.
Czytaj też: Promocja Lenovo na laptopy z serii Yoga, IdeaPad i Legion. Czeka zwrot gotówki
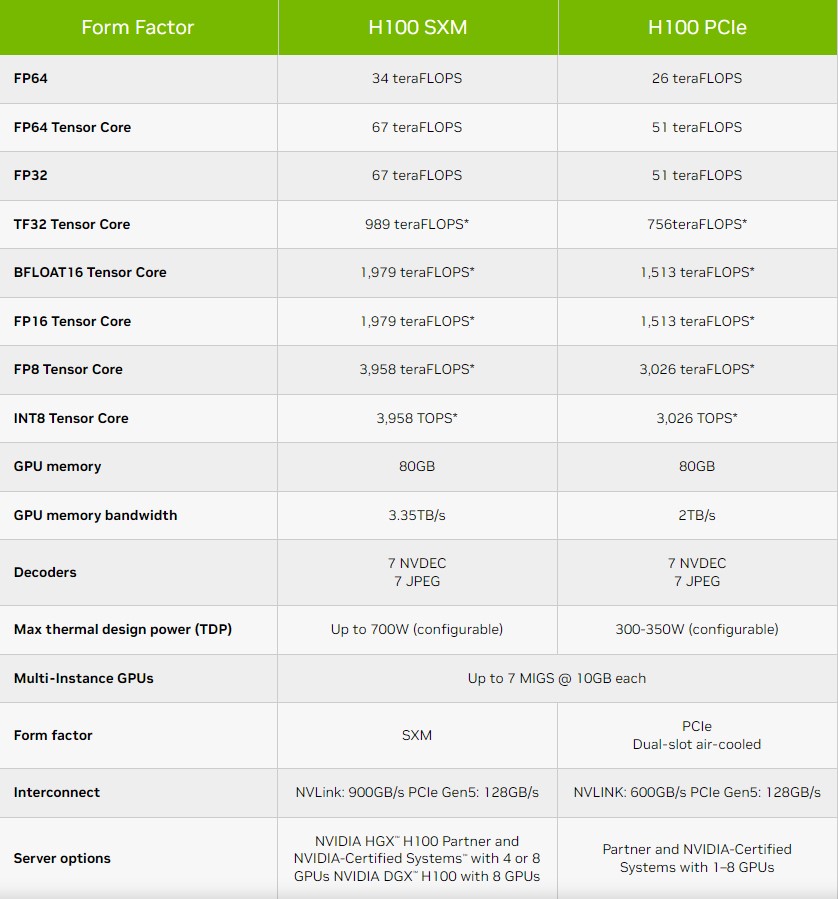
Następne lata (pierwsze dostawy będą mieć miejsce w pierwszym kwartale 2023 roku) upłyną więc pod znakiem NVIDIA Hopper H100 w wersji na złącze PCIe (o TDP 350 W) oraz SXM (700 watów), które doczekały się właśnie aktualizacji swoich możliwości. Wydajność FP64 wzrosła z 30 do 34 TFLOPs, a FP32 z 60 do 67 TFLOPs względem wcześniejszych estymacji, podczas gdy wydajność w obliczeniach z udziałem rdzeni Tensor nieco spadła. W ogólnym rozrachunku oznacza to, że akcelerator z GPU o 16896 rdzeniach CUDA będzie cechował się wyższym taktowaniem GPU, niż wcześniej (nie 1775 MHz, a prawie 2000 MHz).
