
Prawdopodobnie Intel zamierza dodać wczesną obsługę AVX 10.2 „512-bit” dla swoich przyszłych procesorów
Jak wynika z obserwacji użytkownika @InstLatX64 na platformie X, który specjalizuje się w analizie zmian w architekturach ISA Intela i AMD, firma Intel planuje przywrócić rozszerzoną funkcjonalność AVX w swoich procesorach desktopowych. Tym razem powrót dotyczy zarówno AVX10, jak i 512-bitowego AVX-512, a nowości te mają zadebiutować wraz z serią procesorów „Nova Lake”.
Czytaj też: Apple rzuca wyzwanie konkurencji. Trwają prace nad wyszukiwarką opartą na AI
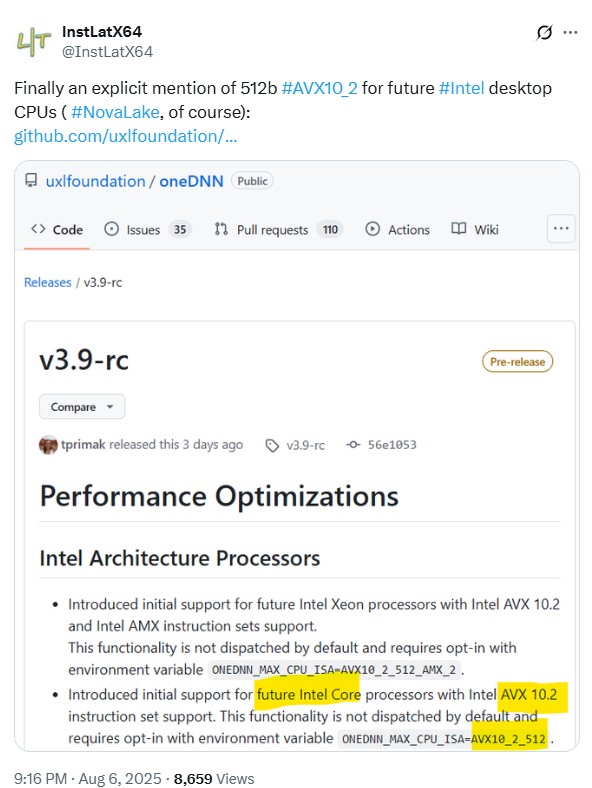
Funkcja umożliwiająca 512-bitowe operacje wektorowe, przekłada się na znaczny wzrost wydajności w specyficznych zastosowaniach. Dotyczy to zwłaszcza zadań związanych ze sztuczną inteligencją, modelowaniem 3D oraz zaawansowanym przetwarzaniem obrazu. Decyzja o usunięciu obsługi AVX-512 z wcześniejszych procesorów klienckich, takich jak Alder Lake i Raptor Lake, była podyktowana problemami technicznymi, ponieważ rdzenie E nie zapewniały pełnego wsparcia dla tej technologii. W rezultacie, przyspieszone 512-bitowe ścieżki danych były dostępne wyłącznie w procesorach serwerowych z serii Xeon.
Czytaj też: Robot właśnie zaprogramował mózg innego robota. Panie Areczku, wiejemy stąd
Kontrastując z podejściem Intela, AMD zaimplementowało pełną obsługę AVX-512 w całej swojej gamie produktów z rdzeniami „Zen 5”, co przełożyło się na wymierne korzyści w postaci wzrostu wydajności w zoptymalizowanych aplikacjach, zarówno na platformach desktopowych, jak i serwerowych. Co ważne, była to również pierwsza sytuacja, w której AMD nie uciekało się do emulacji 512-bitowego AVX, która wcześniej polegała na dzieleniu danych na dwie 256-bitowe jednostki i przetwarzaniu ich w dwóch cyklach.

Czytaj też: Przepustowość do 1 TB/s już w 2028 roku. Wszystko dzięki PCI Express 8.0
Nic więc dziwnego, że w obecnej sytuacji grupa niebieskich dążąc do odzyskania przewagi, planuje przywrócić AVX w swoim portfolio produktów klienckich. Taka decyzja nabiera szczególnego znaczenia w kontekście rosnącej liczby lokalnie działających modeli AI, gdzie każdy element wydajności staje się kluczowy.
