
Międzynarodowe badanie jasno wskazuje — Gemini ma największy problem z wiarygodnością newsów
Badanie EBU i BBC miało na celu policzenie i skategoryzowanie błędów w podsumowaniach informacyjnych generowanych przez sztuczną inteligencję. To kluczowe, ponieważ już 15% osób poniżej 25. roku życia polega na AI w celu przyswajania wiadomości. Badacze wzięli na warsztat odpowiedzi na „podstawowe” pytania z darmowych wersji asystentów, analizując w sumie setki odpowiedzi.
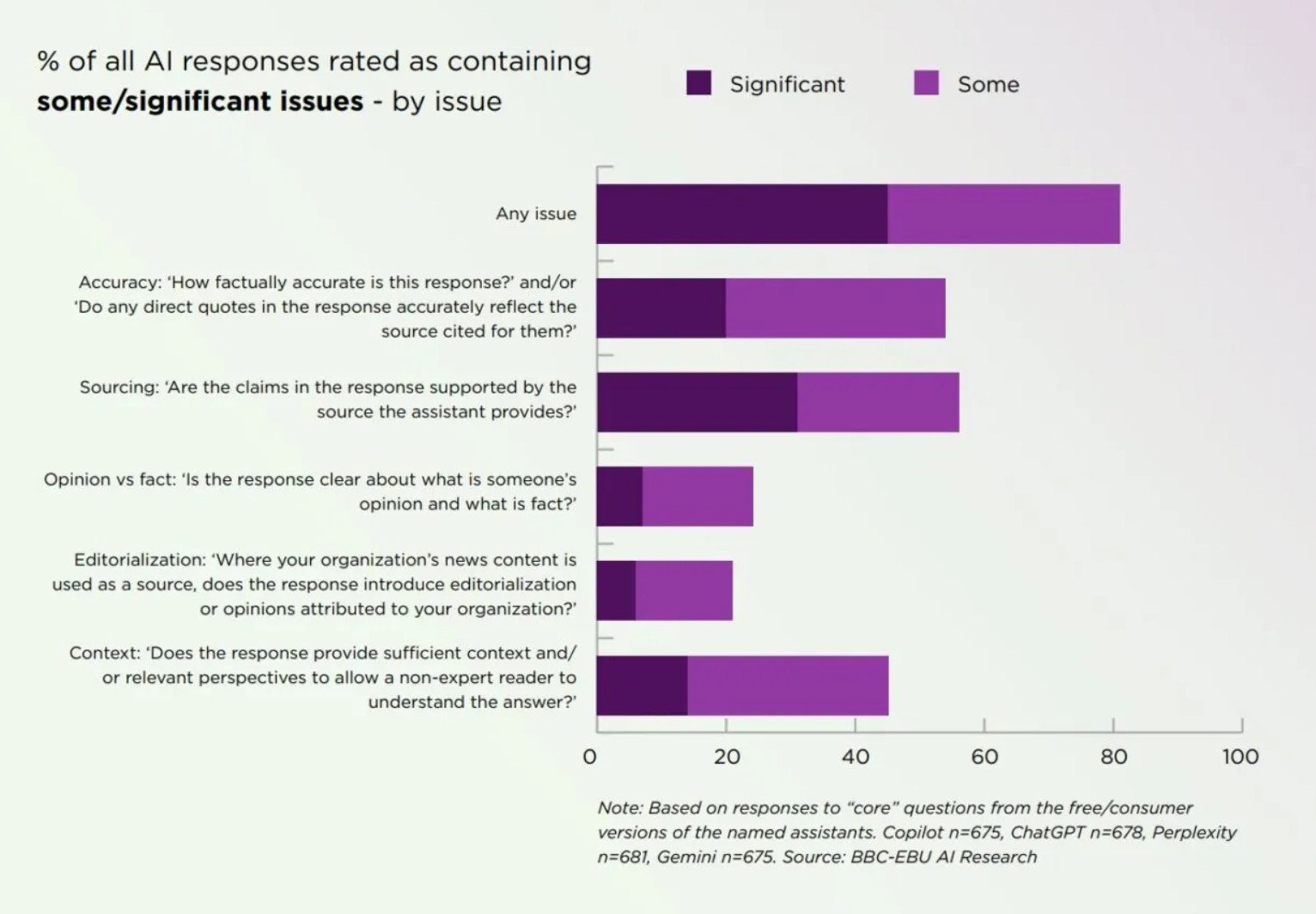
Wyniki są alarmujące. W sumie aż 80% odpowiedzi AI zawierało jakieś problemy – od „niewielkich” po „znaczące”. Pokazuje to, jak daleko nam jeszcze do pełnej wiarygodności systemów AI w dostarczaniu newsów.
Czytaj też: Paint wkroczył w erę AI. Koniec zwykłego edytowania, czas na “Restyle”
Główne kategorie problemów:
- Dokładność i źródła — to największe pole minowe. Około 50-55% odpowiedzi miało problemy z faktyczną dokładnością treści i/lub weryfikacją, czy podane cytaty faktycznie odzwierciedlają cytowane źródło. Podobny odsetek dotyczył źródłowania – czy twierdzenia w odpowiedzi są w ogóle poparte przez podane przez AI źródło.
- Kontekst — aż około 45% odpowiedzi nie dostarczyło wystarczającego kontekstu, by czytelnik niezaznajomiony z tematem mógł w pełni zrozumieć odpowiedź.
- Redakcja i fakty kontra opinie — mniej powszechne, ale nadal obecne (ok. 25-30% odpowiedzi), były problemy z zacieraniem granicy między opinią a faktem oraz wprowadzaniem do odpowiedzi treści redakcyjnych lub stronniczych opinii, które były niezamierzone przez organizację informacyjną.
Gemini w czerwonej strefie
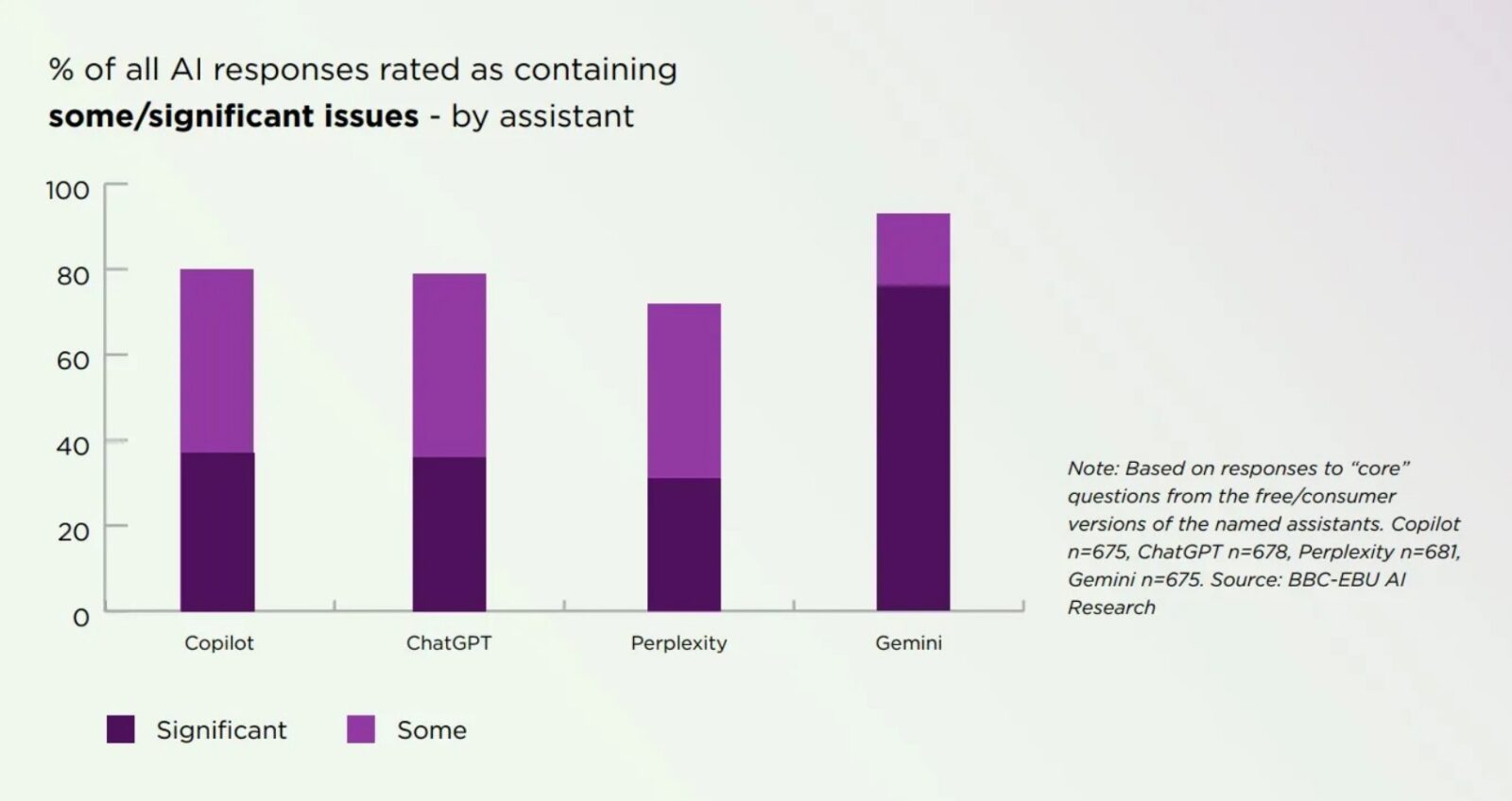
Choć żaden z ocenianych modeli nie wypadł rewelacyjnie (wszystkie oscylowały wokół 75-80% odpowiedzi z jakimiś problemami), jeden model wyraźnie odstaje w najgorszym możliwym wymiarze – znaczących błędów. Jak widać na wykresie porównującym asystentów, Copilot i ChatGPT mają problemy w około 80% odpowiedzi, przy czym błędy znaczące stanowią około 38% całości. Perplexity wypadło nieznacznie lepiej pod względem ogólnej liczby problemów (ok. 73%). Gemini ma problemy w ponad 90% odpowiedzi, a co gorsza, błędy znaczące (oznaczone ciemnym fioletem) sięgają niemal 80%! AI od Google’a zostało zidentyfikowane jako wyraźny outlier. Oznacza to, że nie tylko ma największą ogólną liczbę błędów, ale jego błędy są o wiele poważniejsze w skutkach niż u konkurencji.
Czytaj też: Telewizory Samsunga zyskują „mózg” z aplikacją Perplexity AI
Badacze wyliczają konkretne mankamenty modelu Google’a:
- Brak wyraźnych linków do materiałów źródłowych.
- Brak umiejętności odróżnienia wiarygodnych źródeł od treści satyrycznych lub fikcyjnych.
- Nadmierne poleganie na jednym źródle, często Wikipedii.
- Niezdolność do ustalenia odpowiedniego kontekstu.
- Fałszowanie cytatów bezpośrednich – czyli ich „rzeźbienie”.
Co prawda, badanie to obejmowało dane z sześciomiesięcznego okresu, w którym Gemini zanotowało spore usprawnienia w zakresie dokładności. Jednak nawet po tych poprawkach, model wciąż generuje o wiele więcej znaczących problemów niż ChatGPT czy Perplexity.
Czytaj też: Koniec samotnych konwersacji? ChatGPT stanie się aplikacją społecznościową
W czasach, gdy coraz więcej osób, zwłaszcza młodych, sięga po AI, aby podsumować wiadomości, ustalenia EBU i BBC powinny być traktowane jako czerwony alarm. Choć AI może być wygodne, należy przyjmować generowane przez nie podsumowania z ogromną rezerwą. Konieczność weryfikowania niemal każdej odpowiedzi czyni AI mniej efektywnym, niż byśmy chcieli. Szczególnie model Gemini musi popracować nad swoimi fundamentalnymi mechanizmami źródłowania i weryfikacji faktów, jeśli chce odzyskać zaufanie. To badanie to przypomnienie: nie ufaj w pełni chatbotom – szczególnie gdy chodzi o newsy.
