
Gigabyte AI TOP ATOM to sprzęt, który bierze filozofię DGX Spark i zamyka ją w produkcie połączonym z ekosystemem AI TOP. Sprzętowo to ta sama klasa, więć możecie liczyć na superchip GB10 Grace Blackwell, jedną wspólną pulę 128 GB pamięci i format mini komputera na biurko, ale Gigabyte dokłada do oryginału własne oprogramowanie AI TOP Utility, które pełni rolę graficznego kokpitu do pracy z modelami. Dzięki temu ATOM nie jest “gołą” płytką z Linuksem, lecz narzędziem, które ma skrócić czas od włączenia do pierwszego działającego prototypu. Więcej na ten temat przeczytacie w dwóch poprzednich artykułach, które wyjaśniają zarówno to, jak działa model sztucznej inteligencji “od kuchni”, jak i przybliżają samą koncepcję i potęgę drzemiącą w DGX Spark.








Pierwsze chwile z Gigabyte AI TOP ATOM
Komputer i zasilacz – to znajdziecie w pudełku AI TOP ATOM, więc samo uruchomienie sprzętu jest proste, bo wystarczy zapewnić mu zasilanie. Zwłaszcza że domyślnie producent aktywował funkcję automatycznego włączenia komputera po utracie zasilania. Niestety poza wizualnymi zmianami obudowy, Gigabyte nie postarał się o okazalsze rozbudowanie wersji referencyjnej, którą oferuje NVIDIA, a szkoda. Tyczy się to zwłaszcza braku dodatkowego portu USB-A, bo ten komputer ogranicza się do czterech USB-C, co utrudnia kompatybilność z peryferiami. Na samo wykonanie obudowy nie można jednak narzekać – solidny metal, duże otwory wentylacyjne, podkładka gumowa na spodzie i ciągle te same kompaktowe wymiary.

Instalacja i pierwsze uruchomienie wyglądają tak, jak obiecuje Gigabyte. Po wstępnej konfiguracji (w tym połączeniem się np. z siecią Wi-Fi w przypadku braku połączenia przewodowego) zainstalowanego już systemu trafiamy do AI TOP Utility i od razu widzimy panel do pobierania modeli, przygotowania danych oraz uruchamiania zadań. Zanim jednak wjedziecie w szczegóły, lepiej udajcie się na stronę DGX Dashboard (http://localhost:11000/) i przeprowadźcie proces aktualizacji sprzętu.
Celem aplikacji AI TOP Utility od Gigabyte jest zdemokratyzowanie dostępu do lokalnej sztucznej inteligencji poprzez trafienie do osób mniej technicznych, a to dzięki terminalowi graficznemu. Innymi słowy, koniec z terminalem, kopiowaniem komend i wgapianiem się w surowy tekst… choć musimy pamiętać, że NVIDIA zaprojektowała AI TOP ATOM bardziej jako sprzęt, którego kontrolujemy nie lokalnie (jak typowego peceta), a zdalnie przez terminal i wszelkiego rodzaju skrypty do np. automatycznego włączania modeli. Dlatego też z poziomu AI TOP Utility zrobicie tylko niewielki procent tego, co można dokonać z poziomu terminala. Więcej o tym możecie przeczytać na dedykowanej stronie NVIDII z konkretnymi poradnikami, których liczba rośnie i obejmuje już nawet kwantyzację do NVFP4.


Warto zresztą pamiętać, że choć AI TOP Utility jest na pierwszym miejscu w materiałach promocyjnych od Gigabyte, to nic nie stoi na przeszkodzie, aby machnąć na to oprogramowanie ręką i robić wszystko z użyciem poradnika proponowanego przez firmę NVIDIA lub całkowicie na własną rękę. Tutaj jest już kwestia tego, jak bardzo zaawansowanymi użytkownikami jesteście.
Co znajdziemy w AI TOP Utility od Gigabyte?
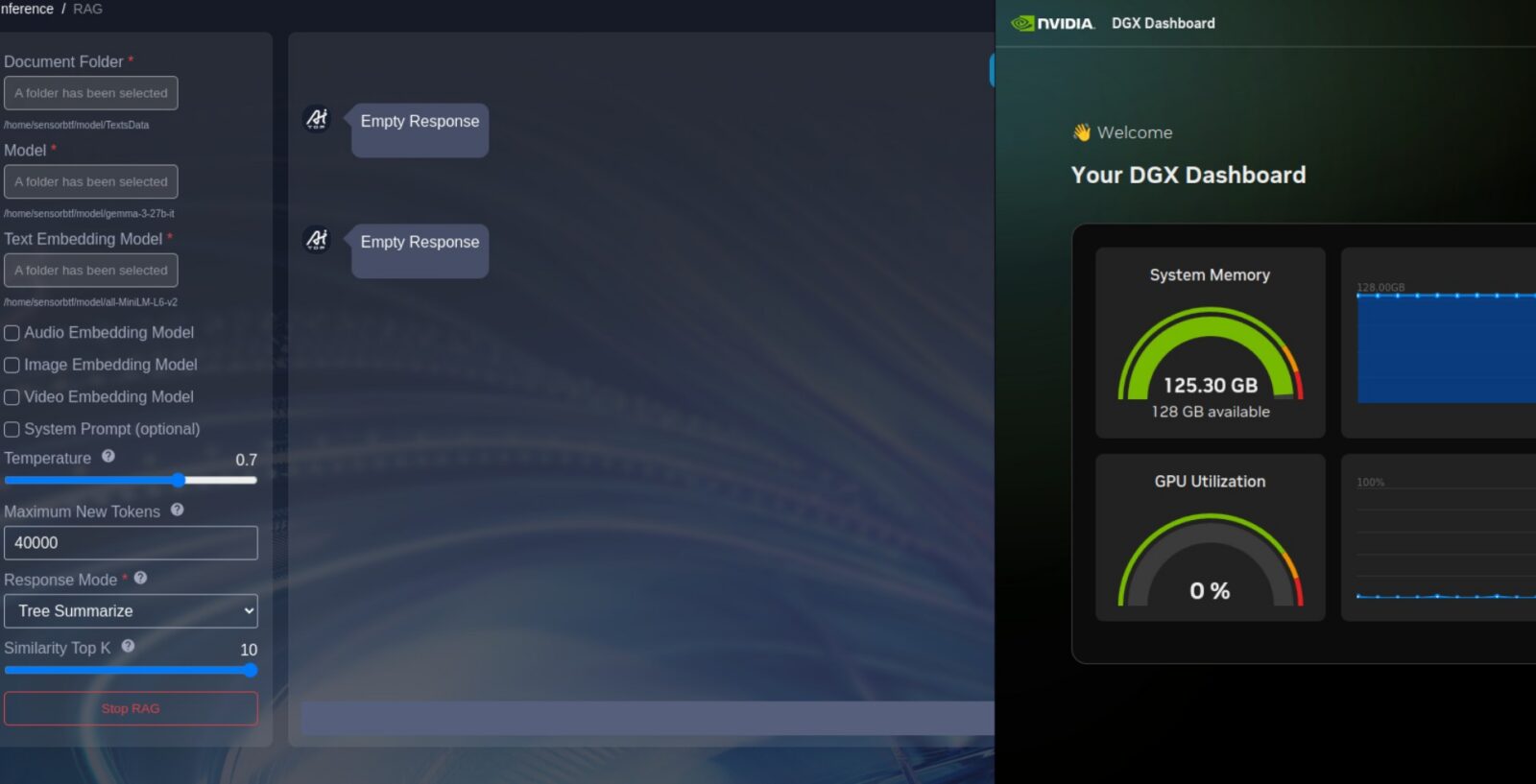
Aplikacja AI TOP Utility została podzielona na sześć głównych menu, a wita nas menu przedstawiające aktualny stan maszyny, które zdradza jedno – oprogramowanie ewidentnie jest ciągle na etapie dopracowywania. O ile aktualne zużycie procesora graficznego (GPU) i centralnego (CPU) oraz zapełnienie pamięci dynamicznej działa poprawnie, tak aplikacja nie odczytuje stanu pamięci masowej i nie radzi sobie z pomiarami temperatury CPU. Gdyby tego było mało, wykresy przedstawiające zużycie pamięci, CPU i temperaturę GPU nie mają nawet uzupełnionej dolnej belki co do okresu pomiarów.
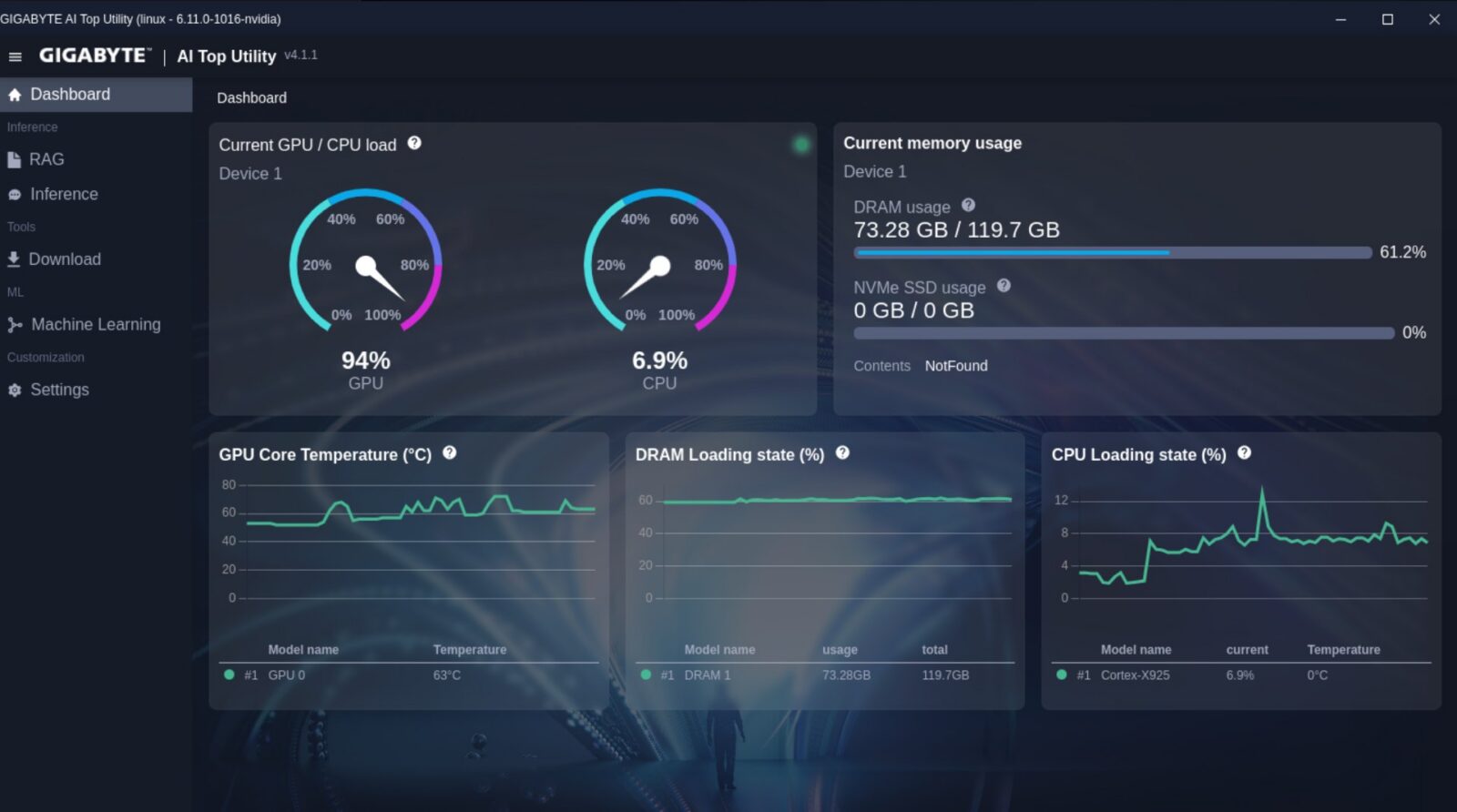
Dlaczego jednak nie widzimy historycznego wykresu zużycia GPU, choć ten związany z CPU już tak? Dlaczego nie możemy aktywować zbierania tych danych do jakiegoś pliku, aby móc monitorować działanie sprzętu w toku np. całego dnia lub nawet tygodnia? To po prostu braki, które utrudniają potraktowanie AI TOP Utility jako oprogramowania, które ma nam zastąpić terminal i inne aplikacje. Im z kolei dalej w las, tym nie jest wcale lepiej.
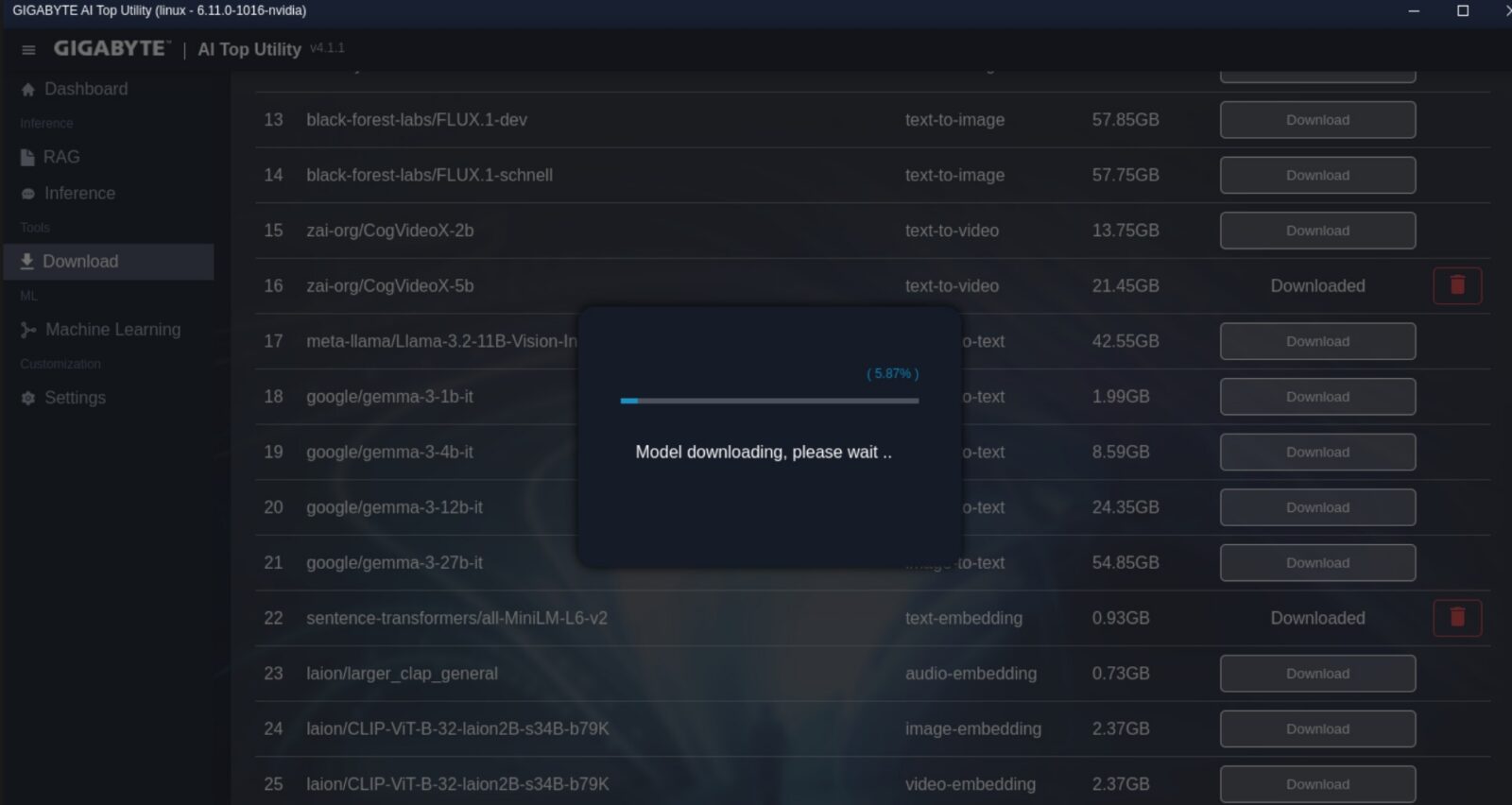
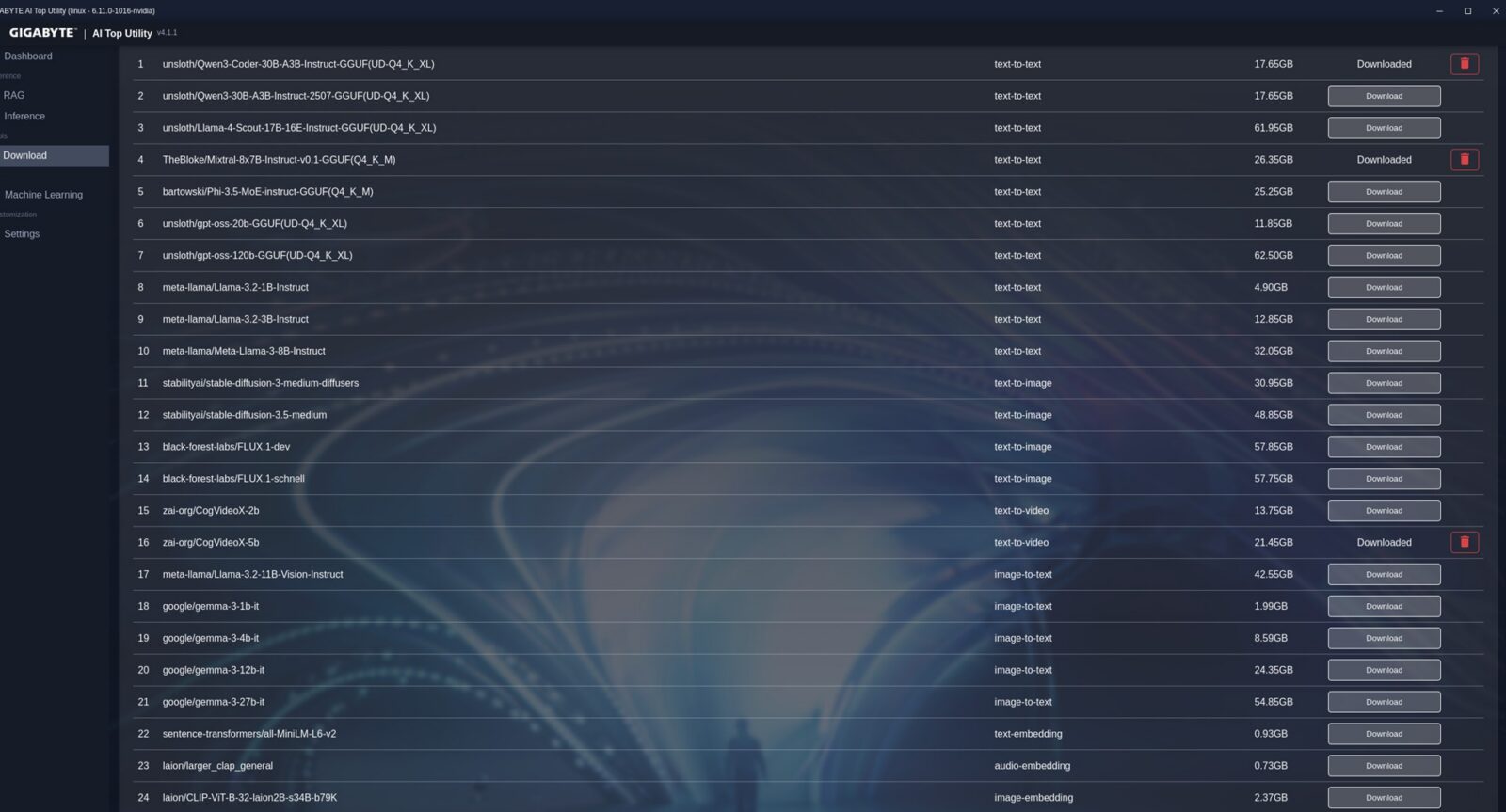
Zakładka ustawień pozwala tylko zmienić język (dostępny jest angielski i chiński), a ta dedykowana modelom do pobrania wspomina (na tę chwilę) jedynie o 25 różnych modelach i choć zapewnia prosty sposób ich pobrania i usunięcia, to okazjonalnie możecie odbić się od ściany, jeśli nie podacie specjalnego tokenu do Hugging Face. Firma Gigabyte nie oferuje bowiem wszystkich modeli z własnego serwera, a korzysta z ogólnodostępnych punktów dostępowych, z czego część wymaga właśnie prostej formy uwierzytelnienia. Z drugiej strony możecie też pobierać modele spoza listy i włączać je z poziomu tejże aplikacji.
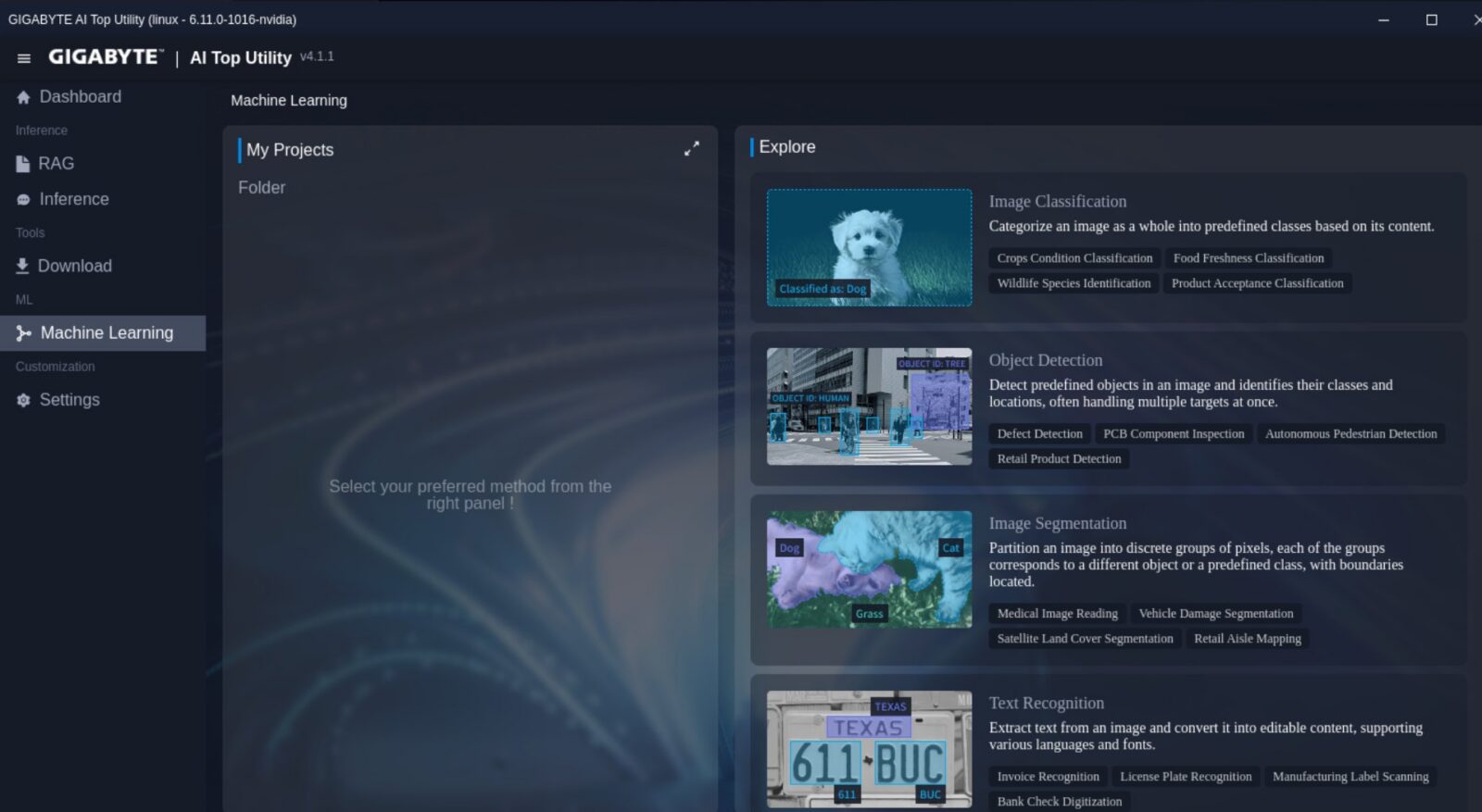
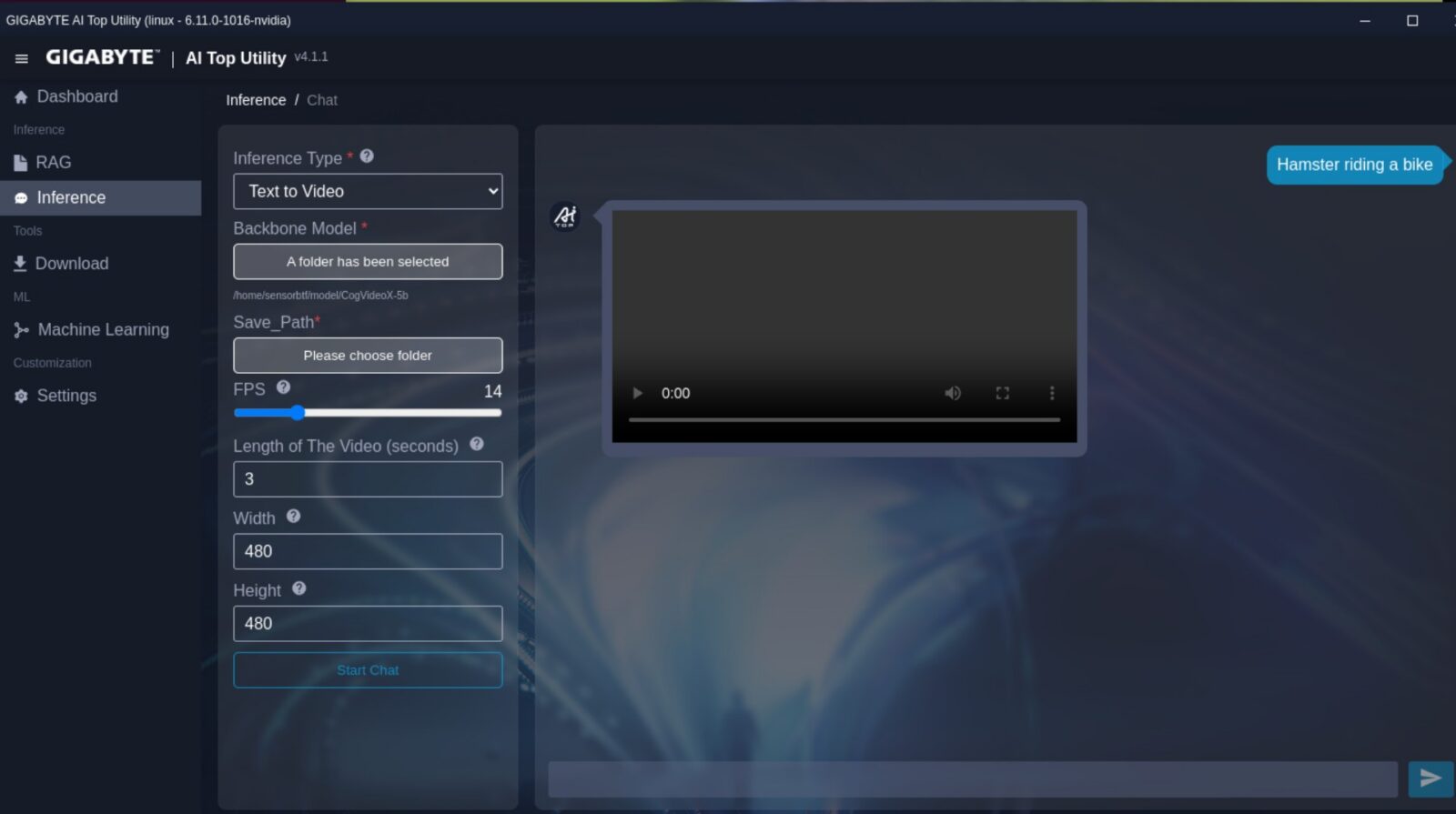
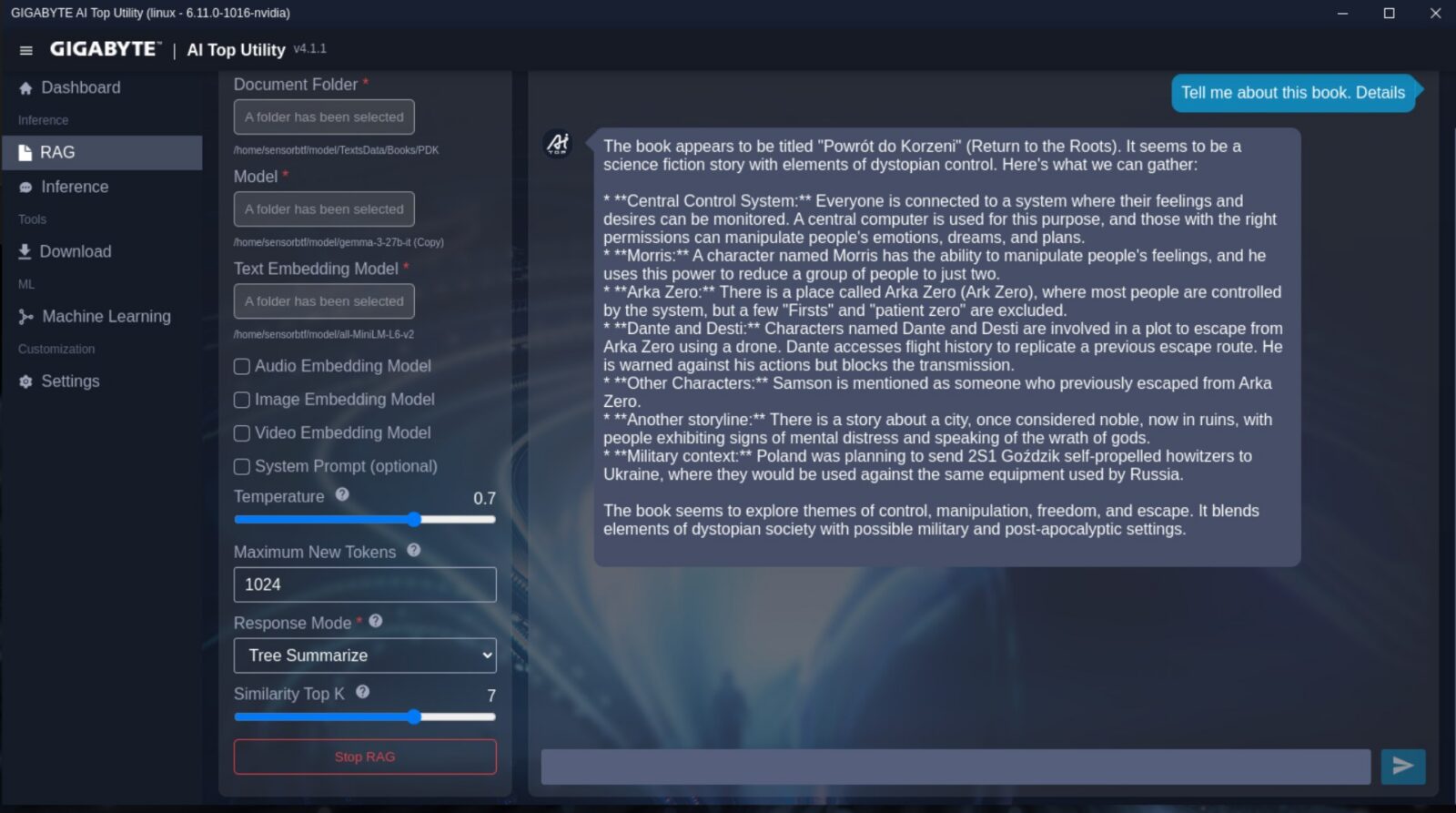
Znacznie ciekawiej robi się przy zakładce Maszynowe Uczenie, która pozwala na stworzenie własnego modelu do klasyfikacji zdjęć oraz ich segmentacji, czy rozpoznawania obiektów oraz tekstu i przepisywania go ze zdjęć. Najważniejsze z punktu widzenia użytkownika zakładki to z kolei Inference oraz RAG. Pierwsza odpowiada ot za aktywację modelu i zapewnienia sobie “własnego lokalnego chatbota” w trybie generowania odpowiedzi tekstowych, grafik czy filmów, a druga dorzuca już “warstwę RAG”, czyli możliwość wskazania modelowi tego, na jakich danych tekstowych ma działać.
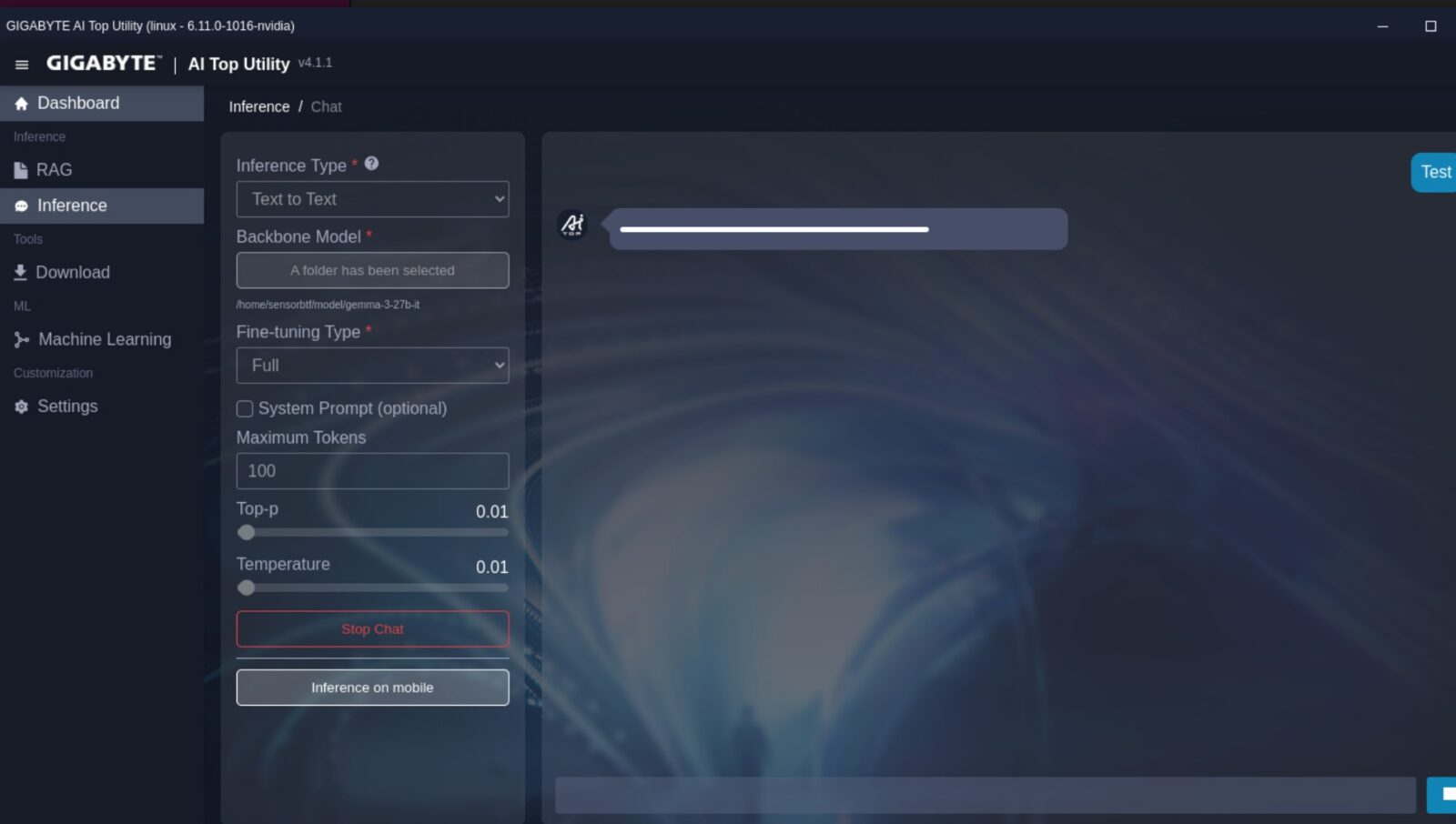

Oprogramowanie AI TOP Utility spełnia więc rolę skracania czasu do pierwszego prototypu. Kluczem w takiej aplikacji (przynajmniej w jej obecnym stanie) jest to, że nie zmusza ona mniej technicznych użytkowników do otwierania terminala, a jednocześnie nie blokuje innych na zamkniętym workflow, bo pod spodem wciąż działa normalny system, w którym możemy uruchamiać własne skrypty oraz narzędzia. Jednocześnie daleko jest tej aplikacji do ideału, bo nie pozwala ona m.in. odpalić jednocześnie dwóch różnych modeli w jednym trybie. Stanowi to już spore utrudnienie, jeśli np. potrzebujecie jednego modelu do programowania, a drugiego do generowania obrazków, do których regularnie odwołujecie się podczas typowej codziennej pracy. Z drugiej jednak strony jednoczesne odpalenie modelu w trybie RAG i Inference jest już możliwe. Nie liczcie też na możliwość zapisania ustawień i aktywacji modelu z automatu po restarcie – tego producent niestety jeszcze do AI TOP Utility nie wprowadził.
Aplikacja Gigabyte AI TOP Utility będzie tylko lepsza
Po skontaktowaniu się z firmą Gigabyte uzyskałem jednoznaczną odpowiedź – będzie tylko lepiej. Firma przyznaje, że obecna wersja narzędzia jest wciąż na etapie dopracowywania i zapowiada dalsze aktualizacje. W przypadku braku wykresu temperatury CPU producent tłumaczy, że przy przejściu na architekturę Arm nie dysponował pełnym zestawem danych z czujników i dopiero ocenia możliwość dopisania tej funkcji w kolejnych wydaniach. Podobnie jest z dokładniejszym podglądem zużycia pamięci oraz eksportem logów do długoterminowego monitoringu – oba elementy trafiły na listę funkcji rozważanych do przyszłych wersji, z uwzględnieniem realnych potrzeb użytkowników i projektu interfejsu.
Gigabyte tłumaczy również, że AI TOP Utility celowo nie pozwala na równoległe uruchomienie dwóch modeli w tym samym trybie. Typowe scenariusze, takie jak połączenie RAG i czatu, potrafią bardzo szybko wypełnić dostępną pamięć, więc producent nie rekomenduje konfiguracji, które w praktyce łatwo kończą się błędami out-of-memory i złym doświadczeniem użytkownika. Z podobnych powodów aplikacja po restarcie systemu nie przywraca automatycznie poprzednio załadowanych modeli – pozwala to ograniczyć pasywne zużycie pamięci zaraz po starcie systemu i zmniejszyć ryzyko, że ATOM od początku pracuje na granicy swoich możliwości. Według deklaracji firmy AI TOP Utility ma być rozwijane w kolejnych wersjach, a część uwag z tej recenzji trafiła już do wewnętrznego planu prac.
Gigabyte AI TOP ATOM na co dzień
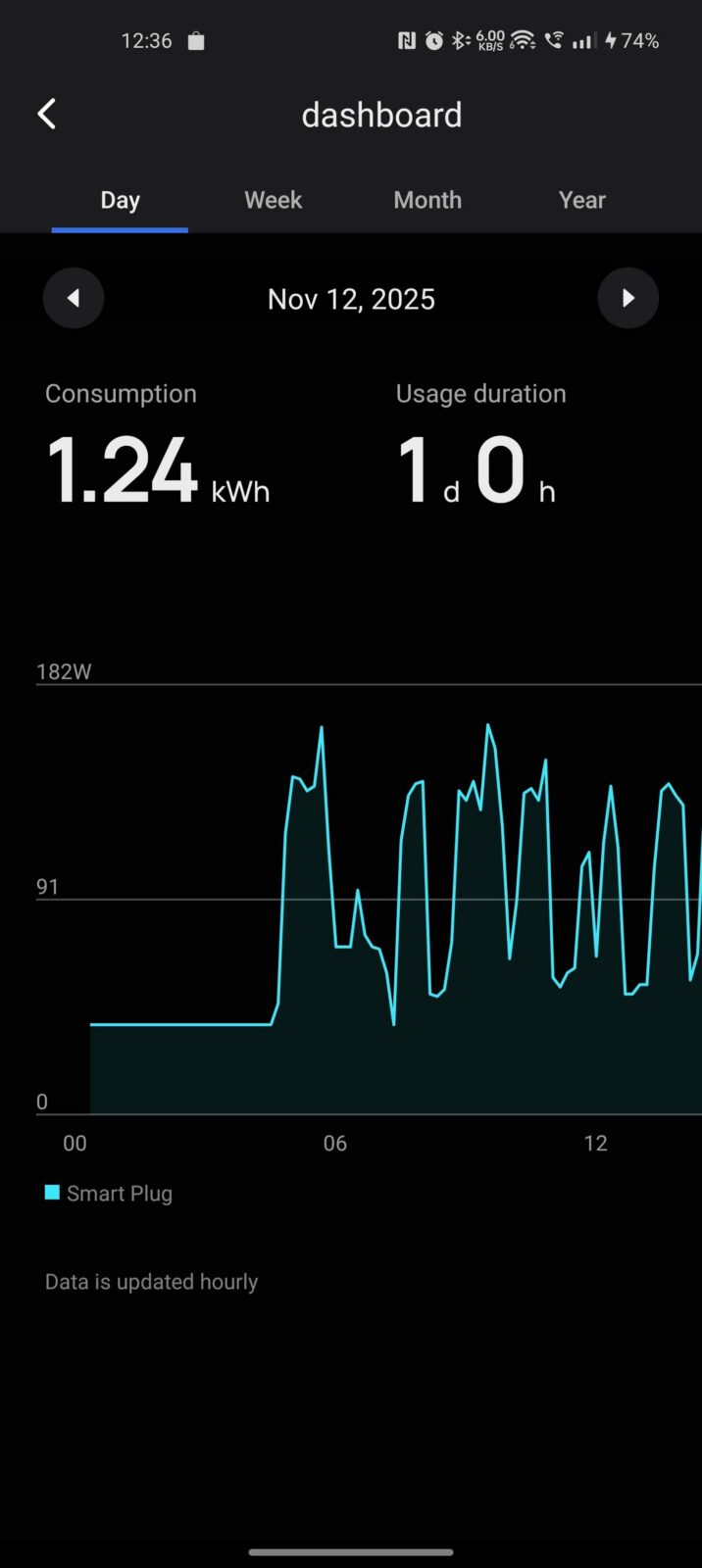
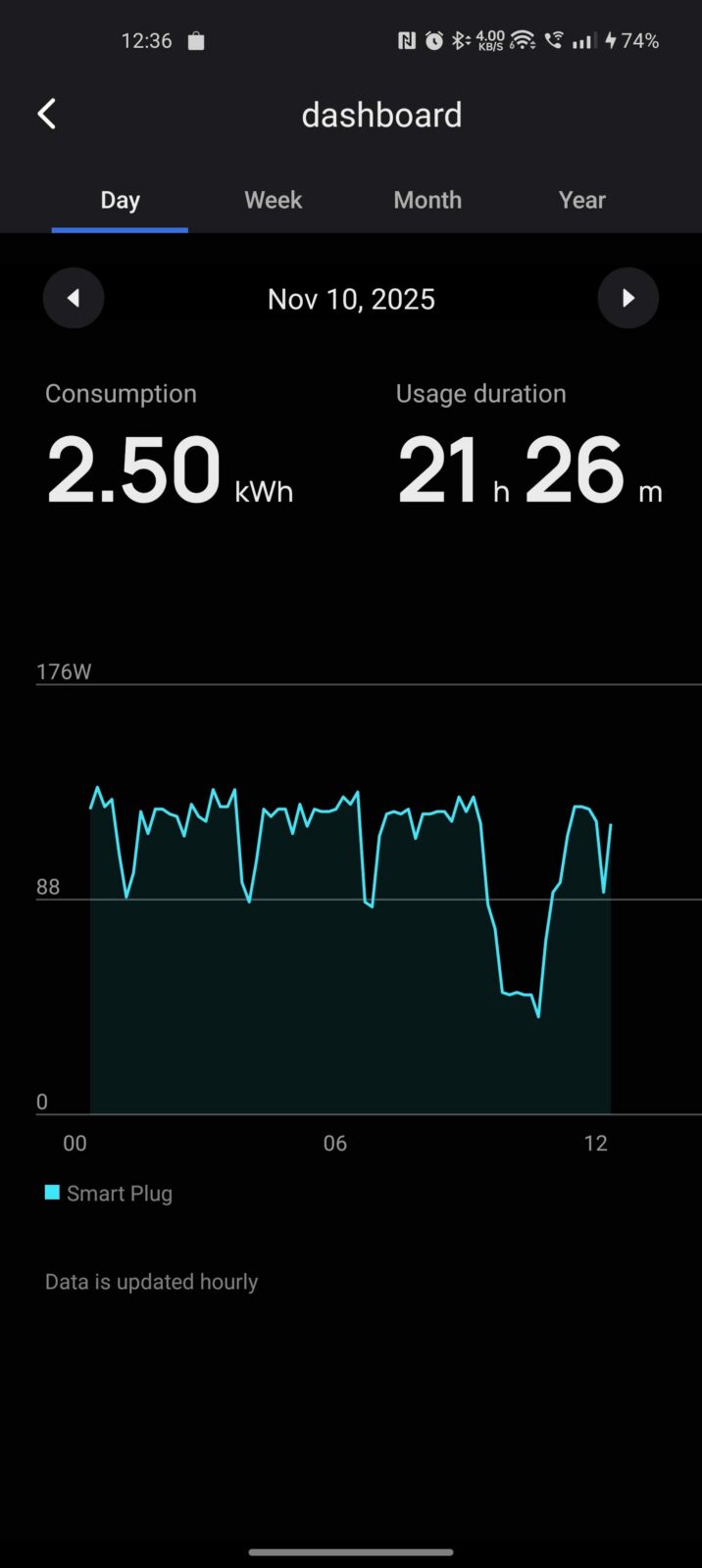
Pierwsze kilka dni z Gigabyte AI TOP ATOM spędziłem tak, jak z typowym komputerem. Wnioski? Responsywny i pozbawiony problemów z płynnym działaniem nawet podczas instalacji programów. Nie powinno być to wprawdzie wielkim zaskoczeniem, bo przecież nie jest to byle komputer, a maszynka z potężnym układem obliczeniowym, ale warto o tym wspomnieć, żebyście nie myśleli, że odpalenie na tym kompie terminala to jedyny sposób korzystania z niego. Trzy grosze do tej płynności dorzuca wydajny dysk SSD firmy Samsung na PCIe 5.0, który to zapewnia bardzo dobre transfery. Spójrzcie tylko:
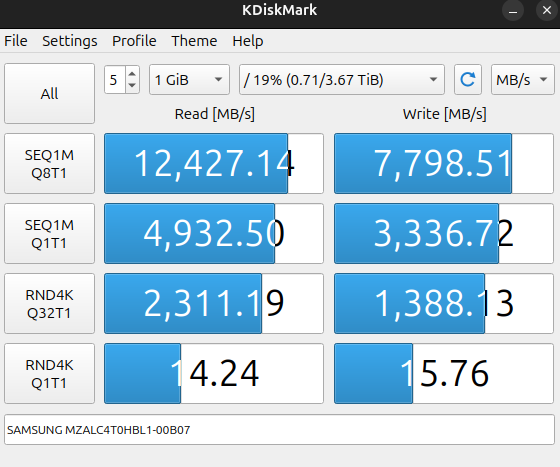

W codziennym użyciu takiego komputera najważniejsze okazują się cztery rzeczy: stabilność, bezproblemowość, płynność działania przy długich kontekstach i niskie zużycie energii. Kiedy bowiem już skonfigurujecie taki sprzęt, to zachowuje się on tak, jak… router. Po prostu działa i zapewnia ciągły dostęp do wydajnej maszynki dla zastosowań SI, a musimy tylko oceniać na bieżąco działanie takiego modelu i ewentualnie aktualizować ustawienia. Tak zresztą podszedłem do tego sprzętu, kiedy wziąłem sobie na cel przetestowanie go w praktyce w mojej codziennej pracy jako game-developera w Unity i Unreal Engine.
Wybór padł na model Qwen3-Coder-30B-A3B (UD-Q4_K_XL), który waży prawie 18 GB. Stworzyłem dla niego skrypt, który automatycznie stawia zdalny dostęp (za pośrednictwem llama-server) i uruchamia model z maksymalnym kontekstem 262144. Resztę ustawień wybrałem już standardowo, o czym możecie przeczytać w tym artykule. Kolejnym krokiem tworzenia takiego lokalnego narzędzia bezpośrednio w IDE było stosowne wskazanie JetBrains Rider lokalnego modelu, który jest dostępny pod adresem maszyny na wskazanym porcie i… tyle. Wszystko ruszyło z poziomu przyjemnego chatu w IDE, a odpowiedzi trafiały do mnie błyskawicznie.
Uprzedzając pytania, nie – nie potrzebujecie tego konkretnego IDE do wykorzystania asystenta w takiej formie. NVIDIA wskazuje zresztą w swoich poradnikach, że najszybciej do takiej zabawy wykorzystać aplikację NVIDIA Sync zainstalowaną na komputerze roboczym, która to zapewnia nie tylko połączenie SSH i dostęp do terminala, ale też upraszcza proces wiązania lokalnego modelu z ekosystemem Cursor i/lub Visual Studio Code. Ba, wśród poradników znajdziecie nawet zestaw instrukcji do tego, jak zacząć Vibe Coding, więc do programowania zaprzęgniecie AI TOP ATOM bardzo szybko. Naturalnie dostęp do modelu jest też możliwy w przeglądarce, bo wystarczy tylko wpisać w nią odpowiedni adres.
Gigabyte AI TOP ATOM w praktyce
Na samym początku trzeba podkreślić jedno – NVIDIA DGX Spark to sprzęt, który powstał z myślą bardziej o naszych biurkach, a nie wielkich serwerowniach. Oznacza to tyle, że należy go traktować bardziej jako taki “prywatny akcelerator do zadań SI” i zabawy m.in. w ComfyUI, a nie coś, co obsłuży pół firmy czy całą bazę klientów. Naturalnie nic nie stoi na przeszkodzie, aby jednocześnie korzystało z niego kilka osób, ale jeśli jednocześnie zaczną one słać skomplikowane zadania do chatu, to szybkość jego odpowiedzi znacznie spadnie.

Czytaj też: Ten komputer jest mniejszy od mojego routera, a bije na głowę wydajność potężnego peceta
Na samym początku rzućmy okiem na wydajność sprzętu w realizacji prostych zadań wykonanych po aktywacji modelu w aplikacji AI TOP Utility:
- Generowanie grafik w modelu FLUX.1-shnell
- 480 × 480 – ~4 minuty
- 1920 × 1080 – ~13 minut
- 3840 × 2160 – 50 minut
- Wygenerowanie 3-sekundowego nagrania w CogVideoX-5b w 23 FPS
- 480 × 480 – 28 minut
- 1024 × 1024 – 2 godziny 20 min
- 1920 × 1080 – 9h 30 min




Z ciekawości podrzuciłem też kilkukrotnie modelowi Qwen3-Coder-30B-A3B z opcją zajmowania się 5 chatami jednocześnie i kontekstem ustawionym na 262144 (wtedy zajmował na start 49 GB pamięci i około 51 GB podczas pracy) zestaw 22 skryptów z mojej gry wykonanej w Unreal Engine do analizy. Raz pojedynczo, a raz w trzech różnych chatach. Wyniki? W przypadku pojedynczego zapytania uwijał się z odpowiedzią średnio w jakieś dwie-trzy minuty (zależnie od tego, jak się “wylosowało”), a trzy identyczne zapytania realizował nie jednocześnie, a wręcz sekwencyjnie w 12-14 minut. Pokazuje to, że wielozadaniowość przy bardziej komplikowanych zadaniach nie jest najmocniejszą stroną AI TOP ATOM, ale akurat to nie powinno nas dziwić.
Czytaj też: Czym jest sztuczna inteligencja i jak mieć ją u siebie lokalnie?

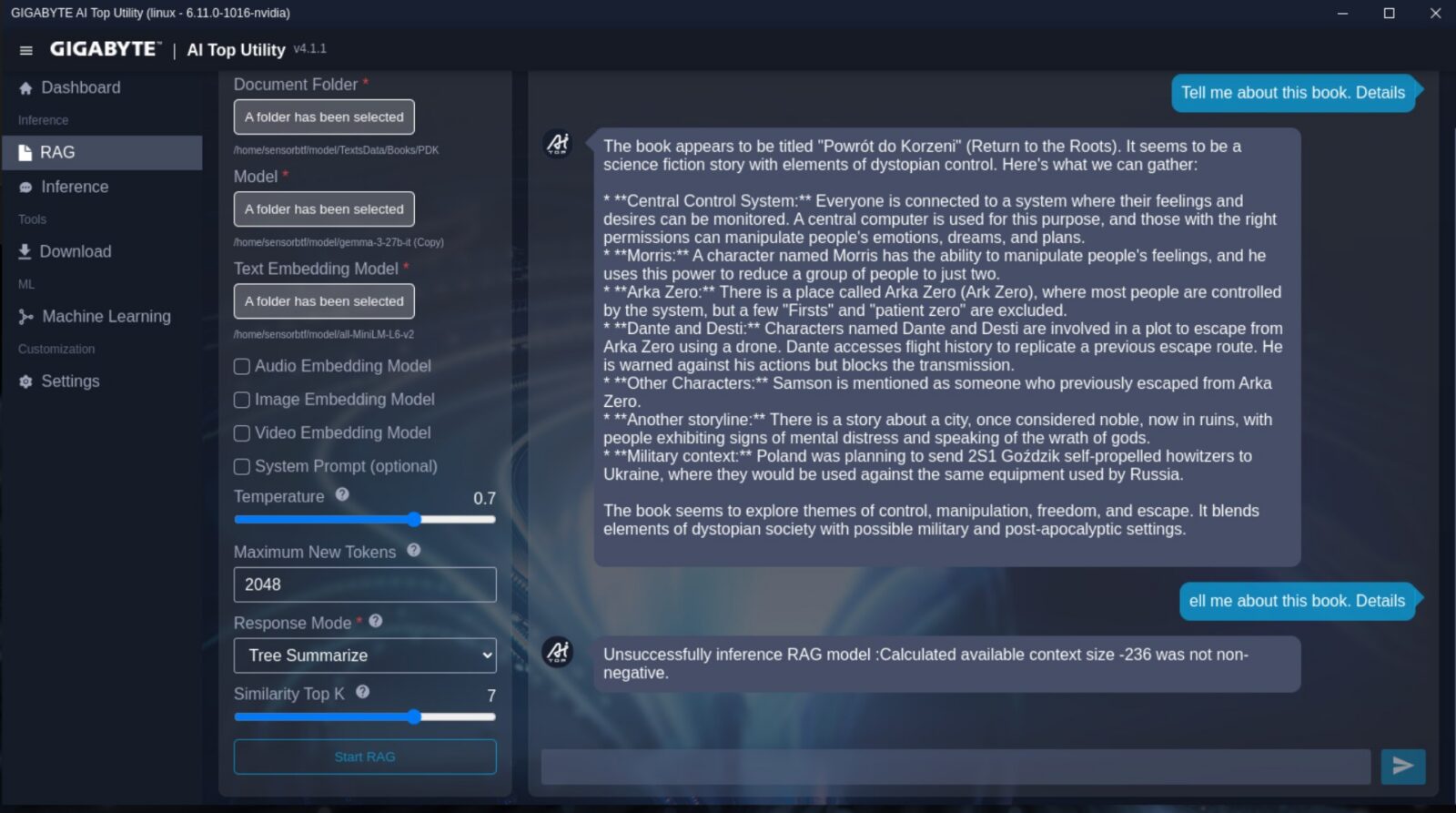
Liczyłem też na to, że sztuczna inteligencja ułatwi mi w pewnym stopniu analizowanie swoich książek. Jednak po wrzuceniu mojej debiutanckiej powieści w model gemma-3-27b-it ze wsparciem all-MiniLM-L6-v2 w trybie RAG z 1024 maksymalnymi nowymi tokenami (110 GB pamięci zajęte), rozczarowałem się wynikami – zarówno responsywnością, jak i dokładnością odpowiedzi. Był to jednak naiwny eksperyment spisany na straty już od samego początku, bo spodziewałem się, że sensowne przemielenie wielkiego dokumentu będzie daleko poza możliwościami nie tylko modelu SI, ale też samego sprzętu, którego zużycie pamięci zbliżyło się do granicy 128 GB. Z zestawem kilku artykułów w miejscu książki AI TOP ATOM poradził sobie jednak bardzo dobrze.
Pojedyncze, nawet skomplikowane prompty do wspomnianego Qwen3-Coder nie powodowały wzmożonej aktywności dwóch wentylatorów obecnych w tym komputerze, ale kiedy zarzuci się AI TOP ATOM kilka zadań jednocześnie, to maksymalny hałas skacze na poziom około 35 dBA z dystansu około 30 centymetrów, sprowadzając się do cichego, niskiego buczenia. Przyrównać można to do poziomu hałasowania bardzo cichego laptopa w trybie energooszczędnym. Czy to zaskoczenie? Niespecjalnie, bo w stanie bezczynności cały sprzęt ten pobiera 45-55 watów, przy aktywnych modelach w oczekiwaniu na zadania 60-70 watów, a podczas pracy dobija najczęściej do 110-120 watów z okazjonalnymi skokami do 170-180 watów, ale tylko wtedy, kiedy np. korzystamy z modeli, a w tle przeprowadzamy inne obliczenia (np. kwantyzację modelu).
Wydajność AI TOP ATOM przy NVFP4
NVFP4 to 4-bitowy format zmiennoprzecinkowy zaprojektowany pod architekturę Blackwell, który zamiast prostego FP4 (E2M1) z pojedynczym współczynnikiem skali stosuje dwuetapowe skalowanie: dla każdego mikrobloku 16 wartości wykorzystuje skalę FP8 E4M3, a na poziomie całego tensora dodatkową skalę FP32. W efekcie lepiej dopasowuje się do lokalnego zakresu danych, zmniejsza błąd kwantyzacji i obniża ryzyko spadku jakości względem FP8, zachowując przy tym korzyści 4 bitów jak do 4x mniejsza zajętość pamięci niż FP16. Kluczowe jest też sprzętowe wsparcie skalowania w Tensor Cores 5. generacji, dzięki czemu NVFP4 przekłada się na stabilniejszą jakość i wyższą efektywność przy długich kontekstach oraz w serwowaniu równoległym, podczas gdy bazowy FP4 częściej “gubi” niuanse rozkładu wartości. W skrócie? FP4 jest lekkie, NVFP4 jest lekkie i bezpieczniejsze jakościowo, bo pracuje na drobniejszych blokach i inteligentnej skali.
Zanim przejdziemy do konkretów, zapoznajmy się z podstawowymi pojęciami, które ułatwią zrozumienie całości. Skupienie się na angielskich określeniach jest o tyle przydatne, że w sieci dominują materiały na temat SI właśnie w języku angielskim.
- Tok/s lub inaczej throughput – liczba tokenów przetworzonych na sekundę. Wyróżnia się podział na osobno prefill tok/s, decode tok/s oraz łączny E2E tok/s.
- KV cache – pamięć kluczy i wartości. Rosnąca wraz z długością sekwencji i liczbą równoległych żądań. Główny konsument VRAM przy długich kontekstach.
- Prefill – to etap wczytywania promptu. Model “czyta” wejście i buduje KV cache. Dominuje przy długich promptach i krótkiej generacji. Kluczowa metryka: prefill tok/s.
- Decode – właściwe generowanie odpowiedzi token po tokenie po zakończeniu prefillu. Dominuje przy krótkich promptach i długiej generacji. Kluczowa metryka: decode tok/s.
- Batching i max_batch_size – łączenie wielu żądań w jedną partię obliczeń. Poprawia tok/s, ale może wydłużyć E2E dla pojedynczych zapytań.
- E2E latency – całkowity czas żądania od startu do pełnej odpowiedzi. Zależy od prefillu, decode, kolejek oraz batchingu.
- TTFT (Time To First Token) – czas od wysłania żądania do pojawienia się pierwszego tokenu w streamie. Ta metryka najbardziej określa “responsywność” modelu w czacie.
- Notacja p×n – p to docelowa długość promptu, n to docelowa długość generacji. Przykład: p1024 n512.
- Prompt tokens i completion tokens – rzeczywista liczba (odpowiednio) tokenów wejścia vs liczba tokenów wyjścia. Suma tych wartości to total tokens.
- Okno kontekstu – limit sumy tokenów rozważanych naraz. Praktyczna reguła: p + n + bufor musi mieścić się w kontekście danego modelu, bo inaczej żądanie zostanie odrzucone lub przycięte.
- Concurrency – liczba równoległych żądań. Zwykle podnosi wykorzystanie sprzętu i liczbę tok/s kosztem TTFT i opóźnienia dla pojedynczego żądania.
- Tok/W – efektywność energetyczna. Ile tokenów na wat dostajemy w uśrednieniu przebiegu. Jest to lepsza metryka porównawcza niż sam tok/s, jeśli zależy nam na możliwie najtańszym modelu w utrzymaniu.
Jak więc czytać wyniki w tekście? Prosto – im niższe jest TTFT, tym szybciej dostajemy w oknie chatu pierwszy token, co pływa na subiektywne odczucie responsywności modelu. Wyższe parametry prefill i decode to z kolei realny zysk zarówno przy długich promptach, jak i rozległych generacjach.
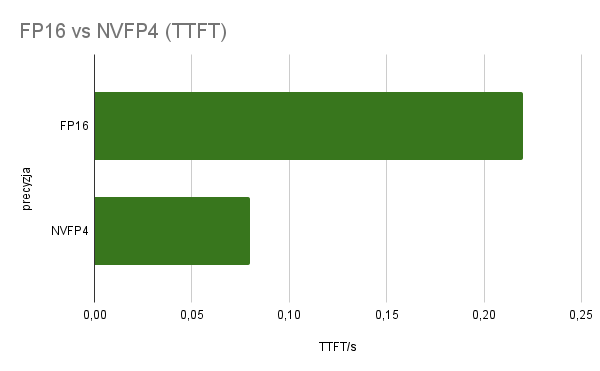
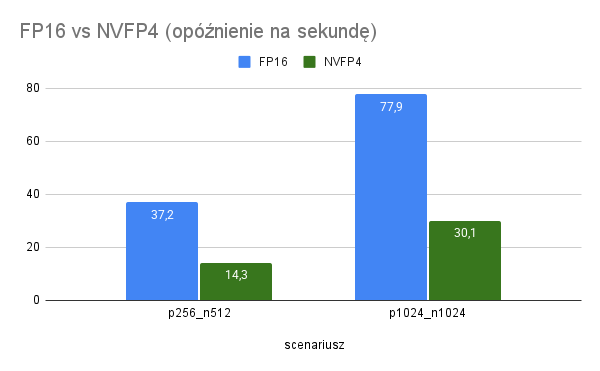
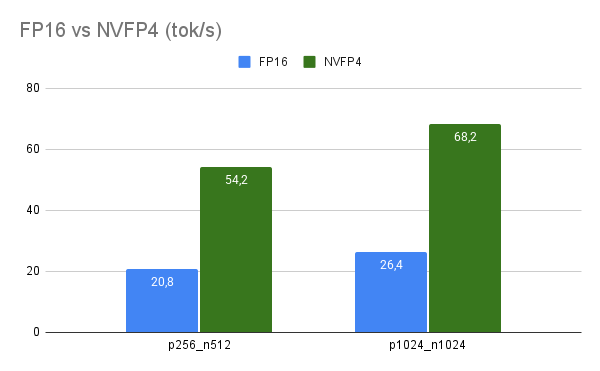
W praktycznych obciążeniach tekstowych NVFP4 przynosi wyraźny zysk względem FP16 i to zarówno w prefillu, jak i w dekodowaniu. Na tej samej maszynie wyniki z mojego zautomatyzowanego testu pokazały medianę przyspieszenia 2,6x w tok/s oraz skrócenie opóźnienia end-to-end mniej więcej o 2,6x w parach, które mieszczą się w oknie kontekstu modelu 8B. Dla przykładu konfiguracja p256 n512 przyspieszyła z 20,8 tok/s do 54,2 tok/s, a średnie opóźnienie spadło z 37,2 sekundy (s) do 14,3 s. W cięższej parze p1024 n1024 NVFP4 zwiększył przepustowość z 26,4 tok/s do 68,2 tok/s, skracając czas z około 77,9 s do 30,1 s. To nie jest jednorazowy strzał, bo TTFT także się poprawia – średnio z ~0,22 s do ~0,08 s, co daje ~2,6x szybsze pojawienie się pierwszego tokenu przy streamingu.
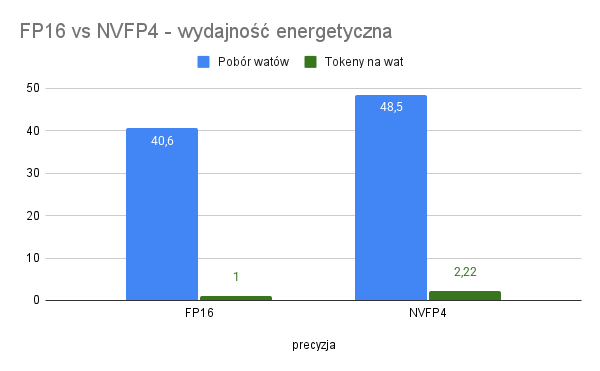
Kluczowe jest to, gdzie NVFP4 “odrabia” ten czas, a widać to w tym, że średnie prefill tok/s rosną ~2.6x, a decode tok/s podobnie ~2.6x, więc zysk nie wynika tylko z lepszego dekodowania krótkich odpowiedzi, ale skaluje się również przy dłuższych generacjach. Użycie NVFP4 powoduje jednak wzrost poboru mocy, choć sama efektywność i tak poszła ostro w górę. Telemetria z nvidia-smi pokazała średnio ~40,6 watów dla FP16 i ~48,5 watów dla NVFP4 przy podobnym zajęciu rdzenia na poziomie ~95%. Mimo wyższej mocy model NVFP4 dostarczał około 2.22x więcej tokenów na wat w uśrednieniu całych przebiegów, więc realny zysk energetyczny jest bezdyskusyjny.
Metodologia była celowo “bliska życiu”. Punktem wyjścia był oficjalny Playbook NVFP4 Quantization przygotowany przez NVIDIĘ dla DGX Spark, czyli zestaw jasno rozpisanych kroków, które pokazują, jak na sprzęcie z GB10 przeprowadzić kwantyzację modelu do NVFP4 przy użyciu kontenera TensorRT i TensorRT Model Optimizer. Sam test objął model DeepSeek-R1-Distill-Llama-8B w dwóch wariantach: FP16 i NVFP4 wygenerowanym przez TensorRT-LLM, na dwóch portach i z tymi samymi ustawieniami. Klient obciążał serwer równoczesnymi żądaniami w dwóch falach na każdą parę p×n, zbierał TTFT przez strumień, liczył tok/s end-to-end oraz rozdzielnie prefill i decode, a następnie zapisywał surowe wiersze do CSV. Z punktu widzenia użytkownika oznacza to tyle, że NVFP4 na GB10 szybciej się odzywa, szybciej liczy i lepiej wykorzystuje moc sprzętu. Innymi słowy, NVIDIA zrobiła kawał dobrej roboty ze swoją unikalną formą kwantyzacji.
Co mówi długotrwałe obciążenie AI TOP ATOM?
Na zakończenie codziennej zabawy z Gigabyte AI TOP ATOM zapodałem sprzętowi kilkunastogodzinny, kompleksowy benchmark, który objął test trzech różnych modeli. Qwen3-Coder-30B-A3B w kwantyzacji UD-Q4_K_XL jako specjalistę od programowania, Gemma-3-27B-IT w Q4_K_M jako kompaktowego generalistę oraz Gemma-3-27B-IT w pełnym FP16 jako punkt odniesienia dla jakości. Generator obciążenia robił swoje, a osobny sampler co sekundę zbierał temperatury i pobór mocy GPU, zapewniając informacje co do długotrwałej wydajności, przeciętnego zużycia energii podczas stałego obciążenia i krótkich szczytów poboru mocy pod maksymalnym obciążeniem. Co najważniejsze, cały test przebiegał bez żadnej niestabilności czy resetowania sprzętu.
Na Gigabyte AI TOP ATOM model Qwen3-Coder-30B-Q4_K_XL okazał się wyraźnie najszybszy w dekodowaniu. Średnio trzymał około 900 tok/s, z medianą w okolicach 600 tok/s i krótkimi szczytami rzędu 2,3 tys. tok/s. Gemma-3-27B-IT w Q4_K_M odznaczała się średnio około 350 tok/s, medianą na poziomie ~290 tok/s oraz okazjonalnymi skokami do ~780 tok/s. Przestawienie tej samej Gemmy na kwantyzację FP16 nie zmieniło rozkładu w decode tak bardzo, jak można by się spodziewać w tym konkretnym teście, bo wyniki wynosiły odpowiednio ~330, ~260 i ~800 tok/s.
Qwen3-Coder-30B-Q4_K_XL w oknie uśrednionego obciążenia zużywał mniej więcej 25 watów mocy procesora graficznego, którego to rozgrzewał do około 60°C, a w krótkich skokach podbijał zużycie do ~75 W i temperaturę do ~71°C. Model Gemma-3-27B-IT Q4_K_M miał wyższy średni pobór, bo około 40 watów i ~70°C, z pikami do ~84 W i ~79°C, a Gemma FP16 plasował się pośrodku, jeśli idzie o temperatury, a energetycznie nieco niżej średniej (około 34 watów i 68°C), ale ze skokami do ~79 W i ~76°C. Co najważniejsze, przez cały czas testów dane nie wskazały na żaden thermal-throttling, ale patrząc po temperaturach i zużyciu energii, GPU ewidentnie nie został popchnięty do granic swoich możliwości. Z jednej strony to dobrze, bo nigdy nie przekroczył krytycznego poziomu temperatury, a jest to sprzęt, który musi być nie tylko wydajny, ale też energooszczędny i trwały, wytrzymując obciążenia nawet przez 24 godziny na dobę i 7 dni w tygodniu.
Test Gigabyte AI TOP ATOM – podsumowanie
Lokalna sztuczna inteligencja nie jest dla wszystkich. Chociaż na papierze mogłoby się wydawać, że NVIDIA DGX Spark to sprzęt typu plug&play, którego łatwo skonfigurować i którego możliwości zawsze przewyższą ogólnodostępne systemy w sieci, to w praktyce wymaga nieco cierpliwości i masy wolnego czasu, jeśli dopiero wchodzi się do tematu własnej SI całkowicie bez doświadczenia. Nie jest to wprawdzie pisanie programów od zera, ale nawet mimo szczegółowych poradników firmy NVIDIA czy dostępnych w Internecie treści, wygenerowanie byle grafiki czy postawienie pierwszego modelu, to nie minuty, a godziny wdrażania się w temat. No, chyba że lecicie z poradnikami tylko na zasadzie “kopiuj-wklej”, aby po kilkudziesięciu minutach nawet nie wiedzieć, co zrobiliście – wtedy czas ten się skróci.
Jeśli zaś idzie o to, jak Gigabyte zrobił z NVIDIA DGX Spark swój sprzęt, to… no cóż, można było do tego podejść lepiej. Zmiana obudowy na bardziej stonowaną nie wystarcza, bo co tu dużo mówić, w takim niereferencyjnym wydaniu przydałby się przynajmniej ten jeden port USB-A oraz potencjalnie lepsze chłodzenie czy też zasilanie, aby układ mógł rozwinąć pełnię swoich możliwości wskazywanych na 140 watów (TDP), z czego sam GPU ma móc pożerać do ~120 watów (wedle NVIDIA). Zwłaszcza że AI TOP ATOM nie jest aktualnie przesadnie głośny, a jego najważniejszym wyróżnikiem jest aplikacja, która… no cóż, nie ułatwia życia w tak dużym stopniu, jakbym tego oczekiwał. Zamiast tego zapewnia przedsmak tego, jak wprowadzić w swoje codzienne życie lokalny model SI, choć trzeba uczciwie przyznać, że niewiele brakuje jej do tego, aby domknąć sens całego ekosystemu.
Warto to podkreślić, bo sam się na tym przejechałem, wczytując się w zapewnienia firmy Gigabyte – AI TOP Utility to nie narzędzie, które zrobi z was “pana sztucznej inteligencji”. Na tę chwilę jest to bardziej “uproszczony graficzny wrapper” dla tego, co można zrobić z poziomu terminala i niestety przyjmuje to formę bardziej średniozaawansowanej zabawy w SI niż stawiania sensownych narzędzi do codziennego użytku. O ile rzeczywiście ułatwia aktywację lokalnego modelu SI i korzystanie z niego, to jednocześnie nie zapewnia wszystkich koniecznych funkcji, które przydają się w praktyce. Przez to wchodzenia do terminala i bawienia się skryptami po prostu nie da się uniknąć.
Jak więc tu ocenić kosztujący 3999 dolarów komputer NVIDIA DGX Spark we wcieleniu AI TOP ATOM od Gigabyte? Werdykt jest ciężki, bo jest to pierwszy taki sprzęt na rynku, który ma zdemokratyzować dostęp do sztucznej inteligencji i uniezależnić nas od usług sieciowych. Kierunek jest fenomenalny, bo przypadek Xbox Game Pass pokazał nam, jak źle kończy się zbytnie uzależnienie od usług w sieci, których cena może znacznie wzrosnąć. Poza tym takie lokalne SI to gwarancja bezpieczeństwa danych i szerokie możliwości, bo nic nie stoi na przeszkodzie, aby w pierwszej połowie dnia robił nam za asystenta w programowaniu, w drugiej połowie pomagał przy pisaniu tekstów, a przez całą noc zajmował się analizowaniem poglądu kamer bezpieczeństwa czy generowaniem np. konceptów do gier lub inspirujących nagrań. Oczywiście wszystko to po wstępnym wytrenowaniu na autorskich tekstach i grafikach, aby ukierunkować model na nasz własny styl.
Patrząc na to, co potrafi taki komputer i ile energii przy tym zżera (typowe komputery z wysokiej półki pobierają nawet kilka razy więcej prądu w tego typu zadaniach), można powiedzieć jedno – szczególnie dziś świat potrzebuje takiego sprzętu. Producenci muszą jednak wykonać jeszcze sporo pracy, aby był on naprawdę przyjazny użytkownikowi, a nie wymagał od niego bardzo dużo zaangażowania. Kierunek jest jednak dobry, a AI TOP ATOM jest bardzo dobrym przykładem tego, że można wziąć ciekawy sprzęt i ułatwić klientom pierwsze kroki w sektorze SI. Jeśli więc wiesz, na co się piszesz i dobrze zdajesz sobie sprawę z ograniczeń oraz możliwości takiego komputera, to po prostu powinieneś go kupić. Jeśli jednak wolisz traktować SI nie jak plac zabaw, a narzędzie, które ma działać bez konieczności zabawy w konfigurację, to jeszcze trochę poczekaj.
