
Książki, strony internetowe, a nawet posty na portalach społecznościowych – nic nie umknie botom przeczesującym sieć w poszukiwaniu autorskich treści, które zasilają bezduszne maszyny, zdolne jednym promptem rozpocząć proces kradzieży stylu danego twórcy. Zbyt radykalnie? Być może, bo w końcu takie Anthropic zdecydowało się zapłacić blisko 1,5 miliarda dolarów za wykorzystanie ponad 440 tysięcy książek do trenowania modeli Claude AI.
To jednak rzadkość na rynku, na którym giganci wolą dogadywać się z Disneyem czy agencją Getty Images, jak robi to OpenAI. Dla pana, panie Areczku, zostaje skanowanie galerii z telefonu przez Facebooka do szkolenia Meta AI oraz przetwarzanie filmów z Youtube przez liczne modele. Nie zawsze wiadomo, czy te modele faktycznie wykorzystały naszą twórczość. Na szczęście powstaje coraz więcej narzędzi, które pozwalają to sprawdzić.
Czy twoją pracę wykorzystano do szkolenia AI? Sprawdź to
Serwis The Atlantic, na co dzień publikujący jakościowe treści, stworzył narzędzie do sprawdzania baz danych wykorzystanych przez modele sztucznej inteligencji. Jego założenie jest proste – wystarczy wpisać nazwisko lub nazwę dzieła, a jeśli to zostało wykorzystane do uczenia maszynowego, pojawi się na liście. Strona podsumowuje też, ile publikacji i w ilu bazach danych się pojawiło.
Zaskoczyć mogą jednak nazwy zbiorów. Zamiast informacji o wykorzystaniu przez Metę, OpenAI czy Google, dostajemy informacje o bazach pokroju HD-Vila-100M, Koala-36M czy Vidgen-1M. Wymienione wcześniej trzy bazy dotyczą wideo, ale i dla książek jest kilka takich zbiorów, jak chociażby Books3, LibGen czy Sleeping-Disco 9M. Firmy zbierają też treści należące do scenarzystów, a te trafiają do takich baz jak między innymi OpenSubtitles.
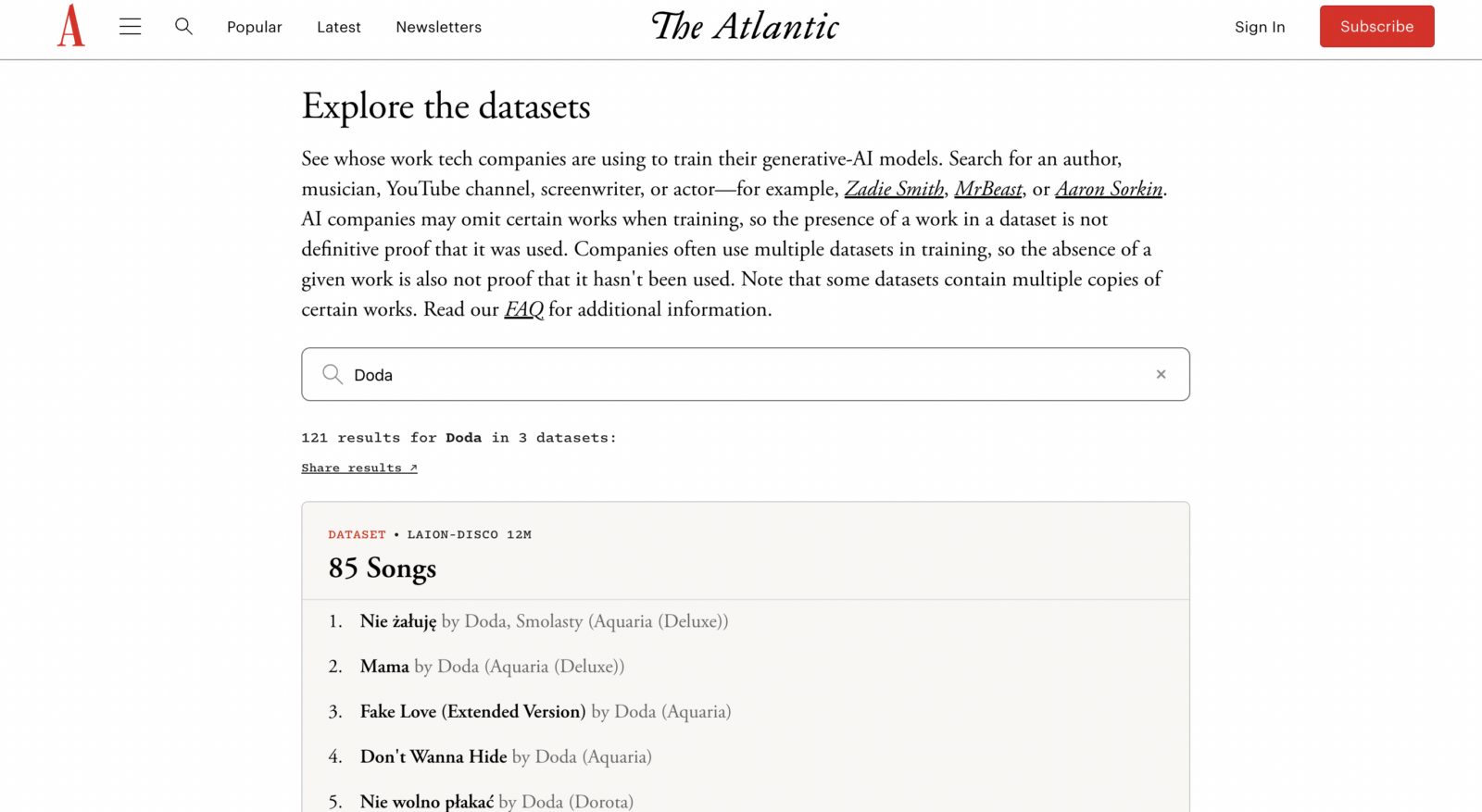
Okazuje się, że największe zbiory wideo czy tekstów są wykorzystywane do tworzenia zbiorów, z których następnie korzystają duże firmy. Strona The Atlantic pozwala podejrzeć informacje na temat narzędzi oraz ich wykorzystania. Nie tylko wielkie bazy jak HD-Vila-100M są pożywką dla technologicznych gigantów. OpenSubtitles gromadzi napisy z 53 tysięcy filmów i 85 tysięcy epizodów seriali, a użyły go chociażby Apple, Anthropic, Meta czy Nvidia.
Czytaj także: Szykujcie portfele. Polska cena GTA VI ujawniona, a droższe gry mogą stać się standardem
Niestety, nie będzie to dla was brama do wszczęcia postępowania z gigantem mediów społecznościowych czy liderem branży technologii. Obecność materiału bądź publikacji w bazie danych nie oznacza, że ten z miejsca został wykorzystany do treningu. Jeśli materiał nie może być przetworzony tak, by nie dało się na jego podstawie wyciągnąć danych wrażliwych, nie może on zostać wykorzystany. W teorii nie powinny być wykorzystywane wizerunki dzieci, ale kazus Stable Diffusion pokazał, że to nie zawsze jest regułą.
Raczej trudno będzie obronić nam nasze dzieła przed botami gromadzącymi treści
Przepisy dotyczące praw autorskich w obliczu rozwoju sztucznej inteligencji nie są do końca jasne. Interpretacje mogą przemawiać na stronę twórców, jak i na korzyść dostawców baz danych oraz modeli. To, co jedni mogą w ramach przepisów Unii Europejskiej nazwać wyjątkiem dla eksploracji tekstów i danych (TDM – Text and Data Mining), dla innych może być plagiatem. Do tego sygnalizowanie sprzeciwu nie jest proste, a większość narzędzi pozwoli nam prędzej zgłosić błąd niż naruszenie własności intelektualnej.
Czytaj także: Netflix utrudni życie nie tylko hakerom. Od lipca samo hasło już nie wystarczy
W przypadku stron internetowych możemy oprzeć się o pliki robots.txt, który po umieszczeniu w głównym katalogu strony blokuje pracę robotów indeksujących i ściągających dane. To jednak rozwiązanie dla tych, którym zależy na postawieniu na swoje, aniżeli na wypisanie się z obecnego trendu. Bez wyszukiwarek i mediów społecznościowych trudno jest, aby twórczość dotarła do szerokiego grona odbiorców, a ich dostawcy wykorzystali swoją pozycję do tego, by wykorzystywać wszystkie dane do trenowania swoich modeli.
