
Nvidia udostępnia wszystkim użytkownikom nowe modele wnioskowania
Ostatnio na blogu z Hugging Face, firma Nvidia zaprezentowała OpenReasoning-Nemotron, czyli zestaw czterech modeli rozumowania (1,5 B, 7 B, 14 B i 32 B) wywodzących się z potężnego DeepSeek R1 0528 (671 bajtów). Kompresując tego „nauczyciela” do mniejszych modeli opartych na Qwen-2.5, NVIDIA umożliwia zaawansowane eksperymenty z rozumowaniem nawet na standardowych platformach do gier, eliminując wysokie koszty GPU i zależności od chmury.
Czytaj też: Koniec ery filmów w Microsoft Store. Użytkownicy Xbox i Windows muszą szukać alternatyw
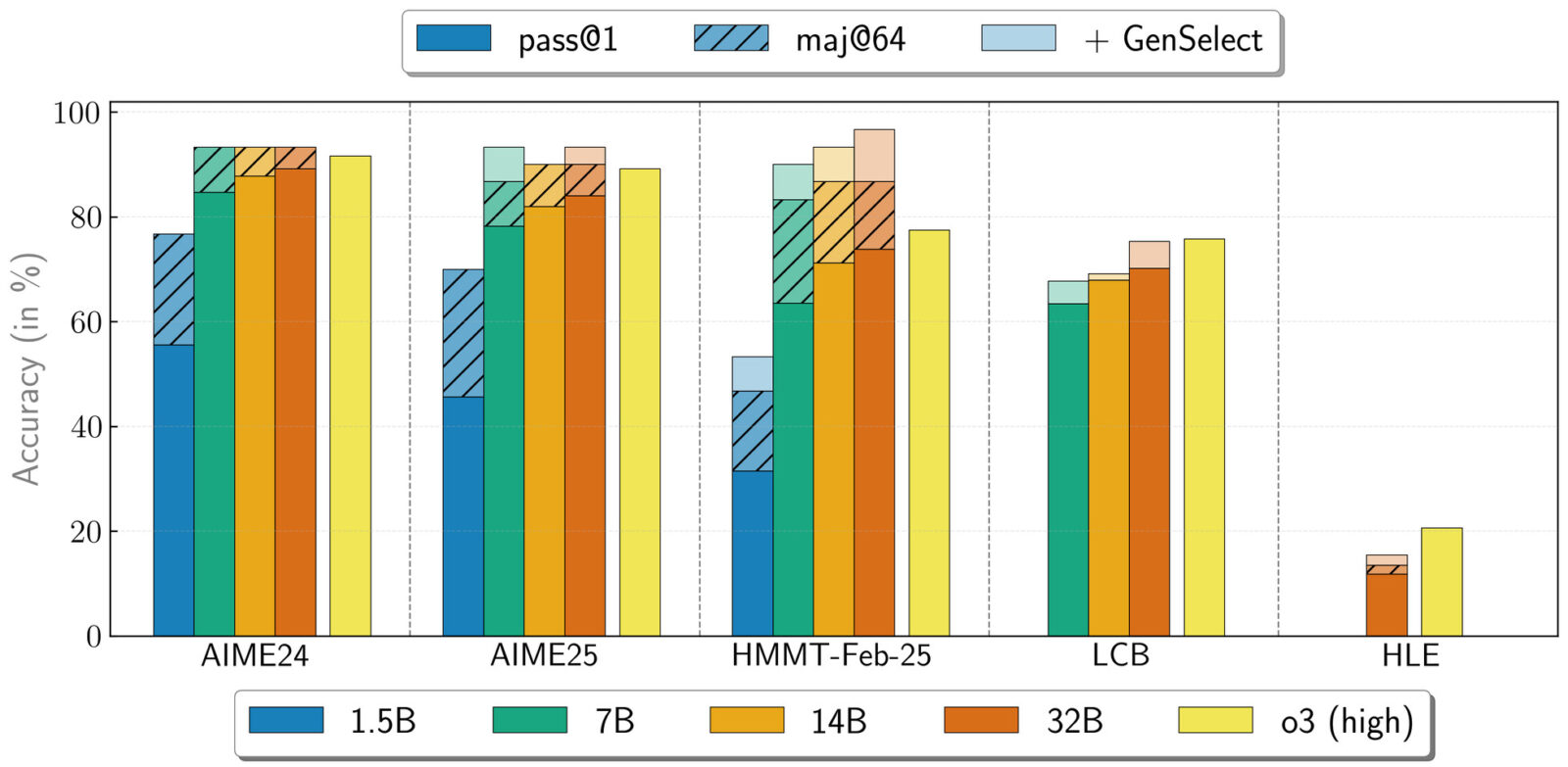
Wykorzystując potok NeMo Skills, grupa zielonych wygenerowała pięć milionów rozwiązań problemów matematycznych, naukowych i programistycznych, a następnie dopracowała je wyłącznie za pomocą uczenia nadzorowanego. Wyniki są imponujące: model 32B osiągnął już 89,2 w AIME24 i 73,8 w lutowym konkursie HMMT, a nawet mniejszy wariant 1,5B uzyskał solidne 55,5 i 31,5.
Czytaj też: Gemini gra w brudną grę, a ceną są wasze dane. Czy da się to zatrzymać?
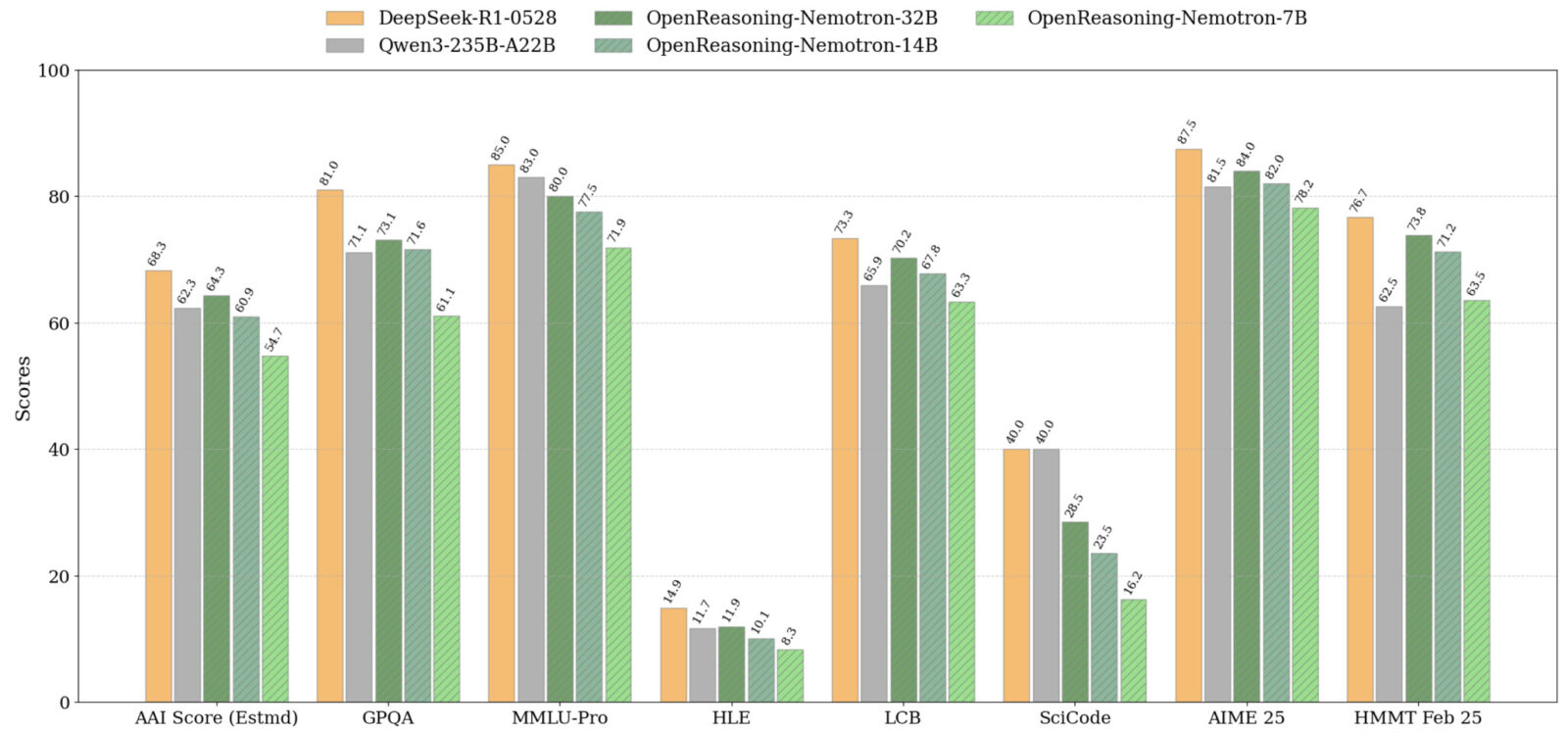
Wszystkie cztery punkty kontrolne będą dostępne do pobrania w Hugging Face, zapewniając solidną bazę do eksploracji rozumowania opartego na uczeniu maszynowym (reinforced learning) lub dostosowywania modeli do konkretnych zadań. Oczywiście przypominam dla niezorientowanych, że te modele nie są stworzone do swobodnych rozmów jak ChatGPT – ich potencjał leży w logice i rozwiązywaniu zadań.
Czytaj też: Tajne starcie matematyków ze sztuczną inteligencją przyniosło niespodziewany rezultat
Dzięki temu, że Nvidia trenowała te modele wyłącznie z użyciem nadzorowanego dostrajania, bez uczenia maszynowego, społeczność zyskuje czyste, najnowocześniejsze punkty wyjścia do przyszłych eksperymentów z RL. Dla graczy i entuzjastów domowych oznacza to, że otrzymujemy model, który może działać całkowicie lokalnie i być bardzo bliski najnowocześniejszym rozwiązaniom, pod warunkiem posiadania wydajniejszego procesora graficznego do gier (mryk, mryk kup nowe karty RTX 50).
