
Przez ostatnie miesiące dużo mówi się o tym, gdzie sztuczna inteligencja (AI – Artificial Intelligence) powinna działać – lokalnie, w chmurze, w odizolowanej enklawie, a może w jakimś hybrydowym modelu, który tylko udaje prywatność. W tej dyskusji zwykle patrzymy na dane, uprawnienia i połączenie z serwerem. Znacznie rzadziej zadajemy sobie prostsze, ale dużo bardziej niewygodne pytanie: co właściwie zdradza sam sprzęt, kiedy model już pracuje? Nowe badanie zespołu specjalistów z KAIST, NUS i Zhejiang University skupia się właśnie na tym, a płynące z niego wnioski są bardzo nieprzyjemne dla całej branży związanej ze sztuczną inteligencją. Kolejny raz okazuje się bowiem, że bezpieczeństwo modelu nie kończy się na szyfrowaniu plików, odcięciu API i szczelnym firewallu. Czasem problemem jest to, że komputer pracujący za ścianą po prostu zostawia po sobie fizyczny ślad.
ModelSpy nie kradnie całej SI. Kradnie architekturę modelu
Badacze opisali atak o nazwie ModelSpy, który wykorzystuje emisję elektromagnetyczną GPU podczas wnioskowania modelu. W praktyce chodzi o to, że karta graficzna, wykonując obliczenia dla sieci neuronowej, emituje sygnały, które da się przechwycić i przeanalizować. Z tych zakłóceń nie odczytuje się “treści myśli” modelu, ale jego konstrukcję, czyli liczbę warstw, ich typy i część parametrów warstw. Mówimy więc o podkradaniu architektury oraz hiperparametrów, a nie o pełnym zrzucie wag 1:1. To rozróżnienie ma ogromne znaczenie, bo architektura modelu nie jest byle ciekawostką dla inżynierów, a szkieletem całego rozwiązania. Wiedza o tym, czy firma korzysta z określonego układu warstw, jak buduje przepływ obliczeń i jakie ma priorytety konstrukcyjne, potrafi bardzo mocno zawęzić pole dalszego ataku. Właśnie dlatego badacze wiążą taki wyciek z łatwiejszym przygotowaniem bardziej klasycznych ataków, a nawet kradzieży funkcjonalności modelu przez budowę lepszego modelu zastępczego.
Czytaj też: AI w rękach oszustów. Nowy raport CERT Orange Polska pokazuje skalę zagrożeń
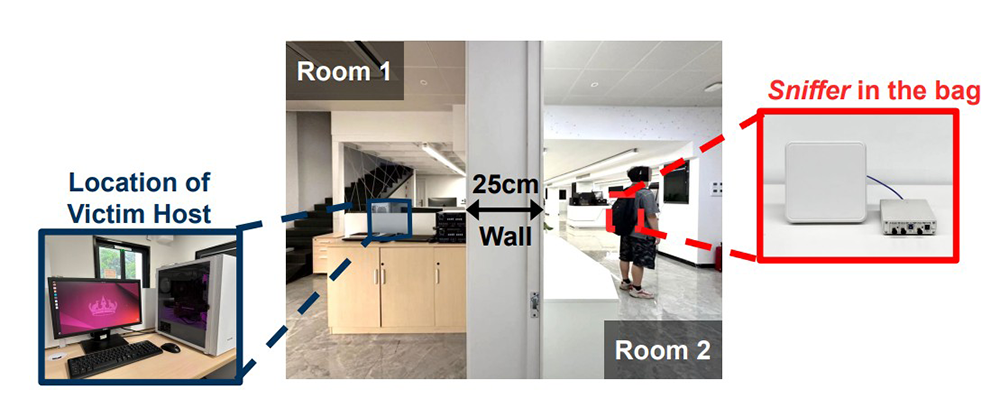
W tym badaniu najbardziej uderza nie tylko skuteczność, ale przede wszystkim sama metoda. ModelSpy nie wymaga zainstalowania malware’u, przejęcia konta administratora ani fizycznego grzebania w środku komputera. System podczas testu działał z dystansu do 6 metrów, także przez ścianę, a testy objęły pięć wysokowydajnych konsumenckich GPU. W warstwie segmentacji warstw osiągnięto do 97,6% skuteczności, a w estymacji hiperparametrów około 94%. Oto więc opowieść o “cyberbezpieczeństwie” przestaje mieścić się wyłącznie w słowie “cyber”, bo atakujący może stać po drugiej stronie ściany, mieć urządzenie ukryte w plecaku i nadal aktywnie kraść. Bardzo dobrze wpisuje się to w szerszą debatę o lokalnej AI, o blokowaniu systemowej AI na urządzeniach służbowych i o architekturach pokroju Private AI Compute, bo we wszystkich tych przypadkach sedno sprowadza się do jednego: zaufanie do AI trzeba dziś projektować nie tylko programowo, ale też sprzętowo i fizycznie.
Jak karta graficzna mówi więcej, niż powinna?
Karta graficzna emituje dalekiego zasięgu sygnały elektromagnetyczne powiązane z pracą takich komponentów jak zegary pamięci czy regulatory napięcia. Podczas inferencji te sygnały są modulowane przez charakterystyczną aktywność sprzętową, a to zwłaszcza przez dostęp do DRAM. Innymi słowy, architektura modelu zostawia po sobie wzór obciążenia, a ten wzór da się odcisnąć w emisji elektromagnetycznej. Jest to więc kolejna odmiana ataku typu side-channel, w którym zamiast patrzeć na kod, patrzymy na jego fizyczny cień.

Nie wszystko da się jednak ukraść równie łatwo. ModelSpy gorzej radzi sobie z nietypowymi projektami warstw, których nie ma w danych treningowych, a przy dużych modelach językowych uruchamianych na wielu GPU temat robi się już znacznie bardziej skomplikowany. Z drugiej strony autorzy sugerują już możliwość rozszerzenia techniki na architektury transformerowe i pokazują ślady sygnałowe dla BERT-a, ChatGPT i Llamy, a w dodatku wspominają wstępny test z anteną paraboliczną działającą z odległości ponad 10 metrów.
Prawdziwy problem zaczyna się dopiero po wycieku
Najważniejsze wnioski z badania nie sprowadzają się do samego “podsłuchu”. Autorzy pokazali też, że architektura odzyskana przez ModelSpy poprawia skuteczność dalszych ataków. W ich studium przypadku, opartym o klasyfikację obrazów i generowanie przykładów adwersarialnych metodą FGSM, wykorzystanie odtworzonej architektury poprawiało skuteczność ataku średnio o 22,8% na CIFAR-10 i 19,8% na CIFAR-100 względem podejścia opartego na modelach zespołowych. Jest to więc różnica między atakiem, który bywa przypadkowy, a atakiem, który zaczyna być budowany pod konkretny cel.
Czytaj też: PLLuM nabiera mocy. IBM i polscy naukowcy budują suwerenną sztuczną inteligencję

Właśnie dlatego ten temat może uderzyć szczególnie mocno w firmy, które budują wartość wokół własnego modelu, ale zakładają, że skoro użytkownik nie widzi kodu ani wag, to wszystko jest w porządku. Nie jest. W świecie AI sama architektura może mieć wartość strategiczną, bo skraca drogę do klonowania rozwiązania, poprawiania ataków i wyciągania wniosków o sposobie działania systemu. Dotyczy to nie tylko startupów, ale też branż takich jak diagnostyka, rozpoznawanie twarzy czy motoryzacja autonomiczna, które autorzy badania wskazują wprost jako naturalne obszary ryzyka.
Autorzy nie skończyli jednak na klasycznym “wykryliśmy lukę, powodzenia”. Proponują dwie główne ścieżki obrony. Pierwsza to zagłuszanie elektromagnetyczne, czyli dokładanie szumu utrudniającego odczyt sygnału, a druga to cyfrowe maskowanie obliczeń przez uruchamianie dodatkowych, pozornych inferencji. Problem polega na tym, że obie metody są kosztowne. Zagłuszanie może wejść w konflikt z łącznością bezprzewodową, bo badacze wskazują szerokie pasmo emisji rzędu 5-6 GHz, a takie maskowanie wydłuża czas inferencji i zwyczajnie kosztuje pieniądze.

Czytaj też: Korzystasz z tego? Jeśli tak, to siedzisz w pułapce i nawet o tym nie wiesz
ModelSpy przypomina, że tradycyjna ochrona sztucznej inteligencji już za mało. Jeżeli model działa na fizycznym urządzeniu, to zdradza też fizyczne sygnały. To przesuwa rozmowę z poziomu “czy dane są dobrze zabezpieczone?” na poziom “czy sama infrastruktura nie opowiada za dużo o tym, co właśnie liczy?”. W tym sensie temat łączy się także z szerszym problemem SI jako “czarnej skrzynki”, o którym wracają dyskusje nawet wtedy, gdy mówimy nie o bezpieczeństwie, lecz o interpretowalności i kontroli nad działaniem modeli. Dobrze pokazują to choćby teksty o tym, jak naprawdę uczą się sieci neuronowe czy o ryzykach wobec prywatności użytkownika.
Źródła: NDSS Symposium, KAIST News
