
Tego typu asystent AI jest dziś osiągalny w sposób łatwiejszy niż można było się spodziewać. Wszystko dzięki Nous Research i frameworkowi agentowemu Hermes, który został zaprojektowany z myślą o stałej pracy, uczeniu się na podstawie doświadczeń i działaniu na sprzęcie użytkownika. Najnowszy materiał RTX AI Garage pokazał mi, że w połączeniu z komputerami NVIDIA RTX, stacjami RTX PRO oraz DGX Spark taki agent zaczyna wyglądać wręcz jak fundament nowego sposobu pracy z komputerem.
Hermes Agent ma działać jak asystent, który z czasem staje się lepszy
Najważniejsza cecha Hermesa sprowadza się do jego pętli uczenia na podstawie pracy. Agent potrafi tworzyć własne umiejętności, poprawiać je podczas używania, zapamiętywać doświadczenia między sesjami i korzystać z historii wcześniejszych rozmów. W praktyce oznacza to, że wykonanie trudniejszego zadania nie musi kończyć się jednorazową odpowiedzią. Hermes może potraktować taki proces jako lekcję, zapisać przydatny schemat działania i wykorzystać go później w podobnym scenariuszu.
Czytaj też: NVIDIA pozytywnie zaskakuje. Gry ciągle zyskują, ale znacznie większa zmiana dzieje się gdzieś indziej
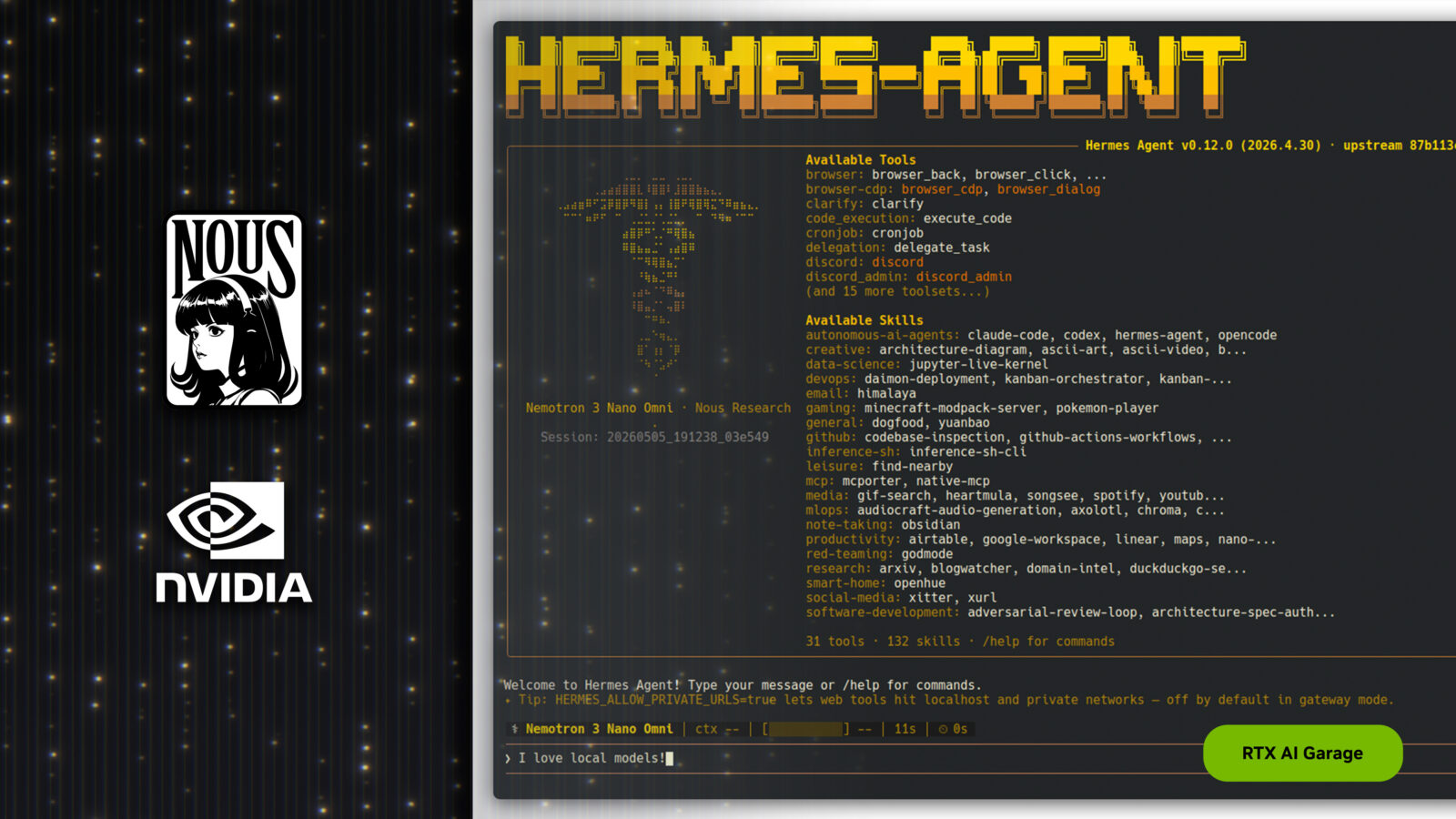
Właśnie tutaj zaczyna się prawdziwa różnica między zwykłym modelem językowym a agentem. Model odpowiada, agent próbuje działać, a taki agent, który potrafi rozwijać własne umiejętności, staje się czymś bliższym cyfrowemu współpracownikowi niż okienku do zadawania pytań. Nie trzeba przy tym zamykać się w jednym dostawcy modeli, bo Hermes jest projektowany jako rozwiązanie niezależne od konkretnego modelu i dostawcy. Może pracować z różnymi endpointami, modelami lokalnymi i usługami, a wybór można zmienić bez przebudowy całego systemu.
NVIDIA chce uwolnić nas od opłat za usługi firm trzecich
Pisałem już o tym przy komputerach-agentach NVIDIA. Cały ten trend demokratyzacji AI ma jeden bardzo ważny cel – przenieść sztuczną inteligencję jeszcze bliżej użytkownika. Efekt? Zamiast wysyłać każdy fragment pracy do chmury, można uruchomić model i agenta lokalnie, na własnym komputerze albo kompaktowej maszynie przeznaczonej do takiej pracy. W przypadku Hermesa nie chodzi wyłącznie o prywatność, choć ta pozostaje ważna. Chodzi także o czas reakcji, ciągłość pracy i swobodę eksperymentowania bez myślenia o każdym zapytaniu jak o kolejnym koszcie, kiedy operuje się na tokenach.
Czytaj też: NVIDIA znów zaskakuje. Tyle gier do ogrania, że głowa mała
Hermes wzorowo wpisuje się w ten kierunek, bo działa jako stale aktywny proces roboczy. Może być dostępny z poziomu terminala, ale też przez komunikatory, takie jak Telegram, Discord czy Slack. Playbook DGX Spark pokazuje zresztą scenariusz, w którym agent działa lokalnie, pozostaje dostępny po restarcie systemu, korzysta z modelu obsługiwanego przez Ollamę i może być wywoływany z telefonu, podczas gdy cała ciężka praca odbywa się na lokalnym sprzęcie. No, naturalnie na byle komputerku takie funkcje nie ruszą, co przypomina mi o pewnym wyjątkowym komputerze od NVIDIA, który nie próbuje udawać zwykłego peceta. Jest to bowiem kompaktowy sprzęt z procesorem ARM do lokalnych obliczeń AI, co podkreśla przede wszystkim 128 GB zunifikowanej pamięci i wydajnością klasy 1 PFLOPS w zadaniach AI.
Czytaj też: NVIDIA znów zasypała graczy nowościami. Jedna z nich od razu mnie zainteresowała

Dobrze łączy się to z tym, o czym pisałem przy lokalnej sztucznej inteligencji oraz przy samym teście niereferencyjnego wariantu DGX Spark w postaci Gigabyte AI TOP ATOM. Lokalna AI nie jest już wyłącznie zabawą w uruchamianie modeli dla samego faktu, że się da. Coraz częściej zaczyna przypominać budowanie własnego zaplecza obliczeniowego do pracy twórczej, programowania, automatyzacji i obsługi prywatnych danych.
To może być początek bardziej osobistej ery komputerów
Hermes Agent jest ważny przede wszystkim dlatego, że dobrze pokazuje, w którą stronę może pójść komputer osobisty wyposażony w sprzęt NVIDIA. Przez lata był on bowiem maszyną do uruchamiania aplikacji. Potem stał się bramą do usług internetowych. Teraz z kolei coraz wyraźniej zmierza w stronę urządzenia, które może mieć lokalną warstwę sztucznej inteligencji, stale obecną obok użytkownika.
